
속도 < 방향
[혼공학습단7기] 혼공머신 Chapter07. 딥러닝 - 인공 신경망, 심층 신경망, 신경망 모델 훈련 본문
07. 딥러닝
07-1 인공 신경망
- 시작하기 전에

럭키백의 성공 이후 타깃 고객의 연령대를 대상으로 패션 럭키백을 진행해보려 한다!
는 사실 패션 mnist 데이터를 사용하기 위한 밑밥..이지만 박해선님의 스토리 라인에 감탄!
<패션 MNIST>
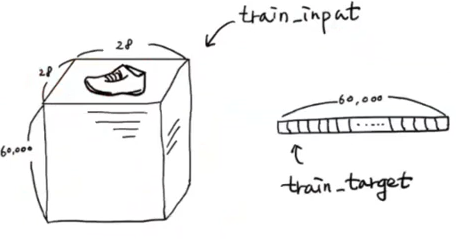
시작하기에 앞서, 머신러닝/딥러닝을 입문할 때 사용하는 데이터셋이 있다. 머신러닝에서 붓꽃 데이터셋이 유명하듯, 딥러닝에서는 MNIST dataset이 유명하다. 이 데이터에는 손으로 적은 숫자로 이루어져 있는데, 패션 mnist는 숫자가 아닌 패션 아이템이 들어가있는 데이터셋이다.
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)
패션 MNIST 데이터셋은 워낙 유명하기 때문에 라이브러리를 통해 import하여 사용이 가능하다. load_date() 메서드는 훈련 데이터와 테스트 데이터를 나눠 반환하는 함수다. 크기를 확인해보면 6만개의 이미지를 활용한 훈련 세트와 1만개의 이미지를 활용한 테스트 세트로 이루어진 것을 알 수 있다.

6장에서 matplotlib으로 이미지를 출력했던 것처럼 샘플을 출력할 수 있다. 이렇게 샘플 이미지를 확인해보면 데이터를 이해하고 주어진 task를 해결할 때 방향 잡기가 훨씬 수월하다.


앞서 출력한 10개의 이미지를 레이블과 함께 출력할 수 있다. 위의 레이블과 출력된 값을 비교함으로써 제대로 labelling되었는지 확인할 수 있다. 또한 레이블마다 6,000개의 샘플이 들어있는 것을 확인할 수 있다.
<로지스틱 회귀로 패션 아이템 분류하기>
6만개의 데이터를 한꺼번에 훈련하는 것보다 샘플을 하나씩 꺼내서 훈련하는 방법이 더 효율적이지 않을까?
이럴 땐 4장에서 배웠던 경사하강법을 사용해볼 수 있다. 이번 실습에서 사용하는 데이터셋의 경우 각 픽셀이 0-255 사이의 정수값을 가지기 때문에 이를 255로 나누어 0-1사이의 값으로 정규화할 수 있다. 정확한 표준화 방법은 아니지만 이미지를 전처리할 때 널리 사용되는 방법이다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)
SGDClassifier 는 2차원 입력을 다루지 못하기 때문에 1차원 배열로 만든 후 크기에 맞춰 지정하면 샘플의 갯수는 변하지 않고 데이터의 차원이 1차원으로 합쳐진다. 변환된 데이터의 크기를 확인해보면 784개의 픽셀로 이뤄진 6만개의 샘플이 준비된 것을 알 수 있다.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss = 'log', max_iter = 5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
경사하강법의 반복 횟수를 max_iter =5로 지정하여 성능을 확인해볼 수 있다.

첫번째 레이블인 티셔츠와 두번째 레이블인 바지에 대해 생각해본다면, 각 레이블마다 다른 가중치(weight) 값과 절편(bias) 값을 적용하여 계산해야 한다. 동일한 픽셀값을 사용하기 때문에 동일한 weight와 bias를 사용한다면 클래스의 구분이 어렵다.
티셔츠를 계산하기 위한 가중치,절편값과 바지를 계산하기 위한 가중치,절편값은 다르다. 회귀를 통해 각 모델 파라미터(가중치,절편)를 찾은 후에는 각 클래스에 대한 확률을 계산하여 얻을 수 있다.
<인공 신경망>
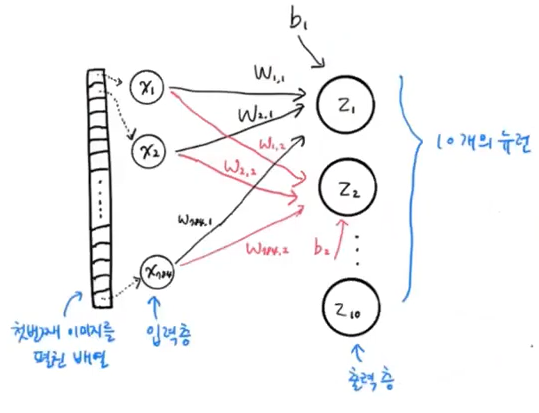
인공신경망(Artificial Neural Network, ANN)은 1장에서 배웠듯이, 딥러닝의 다른 이름이기도 하다. 그림으로 신경망을 나타낸다면 위와 같이 나타낼 수 있는데, z1, z2, ..., z10 의 항목들은 티셔츠, 바지,... 등의 항목이다. 여기서 클래스가 총 10개 이므로 z10까지 계산을 하고, 이를 바탕으로 클래스를 예측한다. 신경망의 최종 값을 만든다는 의미에서 출력층(output layer) 이라고 부른다.
인공신경망에서는 z 값을 계산하는 단위를 뉴런(neuron)이라 부르는데, 유닛(unit)이라 부르기도 한다. x1, x2, ..., x784 까지의 항목은 입력층(input layer) 이라 부르는데, 입력층은 픽셀값 자체이고 특별한 계산을 수행하지는 않는다.
z1을 만들기 위해 x1픽셀에 곱해지는 가중치는 w1,1 이라 쓰고 z2를 만들기 위해 x1픽셀에 곱해지는 가중치는 w1,2 이라고 표기하였다. 절편은 뉴런마다 하나씩이기 때문에 b1, b2 등으로 표기하였다.
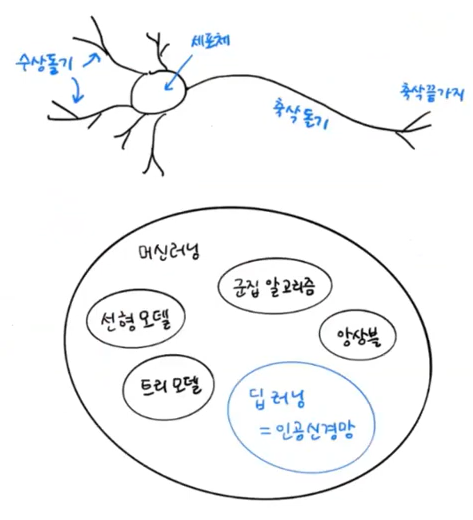
인공 신경망의 발견으로 올라가자면, (생물학적) 뉴런은 수상 돌기로부터 신호를 받아 신호체에 모은다. 이 신호가 어떤 임계값(threshold)에 도달하면 축삭 돌기를 통해 다른 세포에 신호를 전달한다. (생물학적) 뉴런이 신호를 전달하는 과정에서 영감을 받아 구현한 것이 인공신경망이다. 인공 신경망은 우리 뇌에 있는 뉴런과 같지는 않지만 머신러닝 알고리즘이 해결하지 못했던 문제에서 좋은 성능을 발휘하는 새로운 종류의 머신러닝 알고리즘이다.
인공 신경망, 혹은 심층 신경망(Deep Neural Network, DNN)을 딥러닝이라고 부른다. 심층 신경망은 여러 개의 층을 가진 인공 신경망이다.
<텐서플로와 케라스>
텐서플로(tensorflow)는 구글이 오픈소스로 공개한 딥러닝 라이브러리다. 이 때를 기점으로 딥러닝에 관심을 가지는 개발자들이 폭발적으로 증가했고, 텐서플로 출시 이후 알파고가 이세돌9단을 이기며 더욱 폭발적으로 딥러닝 분야가 성장하였다.
텐서플로는 저수준 API와 고수준 API가 있는데, 케라스(keras)가 고수준 API다. 딥러닝 라이브러리가 머신러닝 라이브러리와 다른점은 GPU를 사용하여 인공 신경망을 훈련한다는 점이다. GPU는 벡터연산, 행렬연산에 최적화되어있기 때문에 곱셈과 덧셈계산이 많은 인공 신경망을 계산할 때 많이 사용한다.

케라스 라이브러리는 직접 GPU 연산을 수행하지는 않고, GPU 연산을 수행하는 라이브러리를 백엔드로 사용한다. 예를 들면 텐서플로가 케라스의 백엔드 중 한개이다. 그 외에도 Theano, CNTK 등의 케라스 백엔드 라이브러리가 있다. 구글은 Tensorflow 2.0 이후 대부분의 고수준 API를 정리하고 Keras API만 남겼다. 그래서 거의 Keras와 Tensorflow는 동일한 개념이라고 생각해도 무방하다. 개인적으로 이러한 역사(?) 를 좋아해서 정리해봤다. ㅎㅎㅎ
import tensorflow as tf
from tensorflow import keras텐서플로에서 케라스를 사용하려면 위와 같이 임포트하여 사용할 수 있다.
<인공 신경망으로 모델 만들기>
로지스틱 회귀에서는 교차 검증을 사용하여 모델을 평가하지만, 인공 신경망에서는 교차 검증을 사용하지 않고 검증(validation) 세트를 별도로 덜어내어 사용한다. 그 이유는
첫째로, 딥러닝 데이터셋은 너무 크기 때문이다. 그래서 따로 검증 세트를 덜어내어 사용해도 검증 점수가 안정적이다.
둘째로, 교차 검증을 계산하는 시간이 너무 오래걸린다. 훈련하는 데만 해도 며칠이 걸릴 수 있는데, 검증까지 한다면..?
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)
print(train_scaled.shape, train_target.shape)
print(val_scaled.shape, val_target.shape)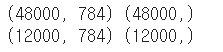
test_size=0.2 로 지정하여 훈련 세트의 20%를 검증 세트로 덜어내었다. 훈련 세트 48,000개와 검증 세트 12,000개로 나뉘었다!
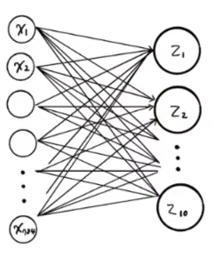
케라스의 레이어에는 다양한 층이 준비되어 있는데, 그 중 가장 기본은 밀집층(dense layer)이다. 바로 위의 그림 중 밀집층의 그림을 보면, 10개의 뉴런이 모두 연결된 것을 생각해본다면 784 개의 픽셀이기 때문에 총 7,840개의 연결된 선을 볼 수 있다. 양쪽의 뉴런을 모두 연결하기 때문에 완전 연결층(Fully Connected Layer) 이라고 부른다.

dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
model = keras.Sequential(dense)밀집층을 만들기 위해 매개변수를 뉴런 개수를 10개로 지정하고, 뉴런에서 출력되는 값을 확률로 바꾸기 위해서는 softmax 함수를 사용한다. activation 매개변수에 함수를 지정할 수 있고, 만약 2개의 클래스를 분류하는 이진분류라면 sigmoid 함수를 사용할 수 있다.
Sequential 클래스를 사용하면 앞서 만든 밀집층의 객체 dense를 전달할 수 있다. 소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수를 활성화 함수(activation function)라 부른다.
<인공 신경망으로 패션 아이템 분류하기>
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])
케라스 모델에서 손실 함수의 종류를 지정해줘야한다. 이진 분류는 binary_crossentropy, 다중 분류는 sparse_categorical_crossentropy 로 사용한다.

이진 크로스 엔트로피 손실을 위해 -log(예측확률)에 타깃값(정답)을 곱할 수 있다. 이진 분류에서는 출력층의 뉴런이 하나이기 때문에 이 뉴런이 출력하는 확률값 a를 사용하여 양성 클래스와 음성 클래스에 대한 crossentropy를 계산할 수 있다.
두번째 뉴런의 활성화 출력만 남기려면 해당 두번째 원소만 1이고 나머지는 0으로 타깃값을 준비해야 한다. 이런 것을 원-핫 인코딩(one-hot encoding)이라 한다.

모델을 돌려보면 evaluate() 메서드가 fit() 메서드와 비슷한 출력을 보여주는 것을 알 수 있다.
# 기본미션
7-1.
Q1. 어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개일까?
> 10개의 뉴런이 100개의 입력과 연결되기 때문에 1,000개의 가중치가 있고 뉴런마다 1개의 절편이 있기 때문에 1,010개의 모델 파라미터가 있다.
Q2. 케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 한다. 이진 분류 모델이라면 activation 매개변수에 어떤 활성화함수를 지정해야 할까?
> 이진 분류일 경우 sigmoid를 사용한다.
Q3. 케라스 모델에서 손실함수와 측정지표를 지정하는 메서드는 무엇일까?
> compile() 메서드를 통해 loss 매개변수로 손실함수를 지정하고 metrics 매개변수에서 측정하는 지표를 지정할 수 있다.
Q4. 정수 레이블을 타깃으로 가지는 다중 분류 문제일 때 케라스 모델의 compile() 메서드에 지정할 손실함수로 적절한 것은 무엇일까?
> 타깃값이 다중일 경우에 'sparse_categorical_crossentropy' 를 사용한다.
# 선택미션
7-2
Q1. 모델의 add() 메서드 사용법이 올바른 것은 어떤 것일까?
> model.add(keras.layers.Dense(10, activation='relu')
Q2. 크기가 300 x 300인 입력을 케라스 층으로 펼치려고 할 때 어떤 층을 사용해야 할까?
> 입력의 차원을 일렬로 펼치려면 Flatten을 사용한다.
Q3. 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화함수는 무엇일까?
> 'relu' 는 이미지 처리를 위해 자주 사용되는 함수이다.
Q4. 적응적 학습률을 사용하지 않는 옵티마이저는 무엇일까?
> 'sgd'는 모두 일정한 학습률을 사용한다.
● 마무리
이번 챕터에서는 딥러닝에서 사용하는 기본적인 개념에 대해 배웠다. 딥러닝은 머신러닝과 다른 부분이 다소 있고, '신경망'이라는 개념이 들어가기 때문에 확실히 입체적으로 접근할 수 있다. 하지만 더 깊게 들어가려면 수학적인 지식이 기본적으로 필요하기 때문에, 선수과목으로 선형대수나 통계/행렬을 배우는 것을 추천한다.
코랩에서 실행한 파일을 공유드리니, 필요하신 분은 다운받아 사용하시면 됩니다.
'개발 > ML,DL' 카테고리의 다른 글
| [혼공학습단7기] 혼공머신 Chapter06. 비지도 학습 - 군집 알고리즘, K평균, 주성분 분석 (0) | 2022.02.19 |
|---|---|
| [혼공학습단7기] 혼공머신 Chapter05. 트리 알고리즘- 결정트리,교차검증,앙상블 (0) | 2022.02.07 |
| [혼공학습단7기] 혼공머신 Chapter04. 다양한 분류 알고리즘- 로지스틱 회귀, 경사하강법, 손실함수 (0) | 2022.01.30 |
| [혼공학습단7기] 혼공머신 Chapter03. 회귀 알고리즘과 모델 규제 (0) | 2022.01.22 |
| [혼공학습단7기] 혼공머신 Chapter02. 데이터 다루기 (0) | 2022.01.11 |



