
목록개발 (56)
속도 < 방향
 Open WebUI 프레임워크 소개
Open WebUI 프레임워크 소개
Open WebUI 깃허브 : https://github.com/open-webui/open-webui GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...)User-friendly AI Interface (Supports Ollama, OpenAI API, ...) - open-webui/open-webuigithub.com Open WebUI란? OpenWebUI는 오픈 소스 LLM(대규모 언어 모델) 웹 인터페이스로, 로컬 AI 모델과 다양한 AI 서비스를 쉽게 사용할 수 있도록 만들어졌다. 처음엔 Ollama를 위해서 만들어진 프레임워크라 이름이 Ollama Web UI였으나, 현재는..
 [검색엔진] 검색 시스템 이해하기 1 - 엘라스틱서치 중심으로
[검색엔진] 검색 시스템 이해하기 1 - 엘라스틱서치 중심으로
작성일 : 2024-10-18레퍼런스 : 엘라스틱서치 실무 가이드1.1 검색 시스템의 이해1.1.1 검색 시스템이란?네이버, 구글 등에서 제공하는 다양한 서비스 중 가장 큰 비중을 차지하는 것은 사용자가 원하는 검색어에 대한 결과를 검색 서비스일 것이다. 이를 부르는 용어도 다양한데 검색엔진, 검색 시스템, 검색 서비스 등 다양한 용어가 혼용되어 불리고 있다. 우선 검색엔진은 광활한 웹에서 정보를 수집하여 검색 결과를 제공하는 프로그램인데, 제공되는 데이터 특성에 따라 구현 형태가 각각 달라진다. 야후(Yahoo)는 디렉터리 기반의 검색 결과를 세계 최초로 제공했다. 요즘에는 대범주(뉴스, 블로그, 카페)에 따른 카테고리별 검색 결과를 대부분의 검색 엔진에서 제공한다. 검색 시스템은 대용량 데이터를 기..
 [Rust Web Development : 러스트 웹개발] 도서 리뷰 및 러스트 프로그래밍 언어 소개
[Rust Web Development : 러스트 웹개발] 도서 리뷰 및 러스트 프로그래밍 언어 소개
last update : 2024-09-26참고 도서 : 러스트 웹 개발 러스트 웹 개발 - 예스24러스트로 뼈대부터 웹 서비스, 테스트, 배포까지!더 빠르고 안전한 웹 애플리케이션을 만드는 최상의 방법!러스트는 시스템 프로그래밍을 위한 안전하고 빠르며 생산적인 언어다. 또한, 개발자www.yes24.com 위 책을 리뷰합니다.1. 개요러스트는 시스템 프로그래밍 언어로, interpreter 언어와 달리 컴파일러가 있다. Go의 garbage colletion 이나 Java의 JVM으로 인한 성능 저하가 없고, 파이썬/루비처럼 읽기 쉽다. C언어만큼 좋은 성능을 발휘하는데, 그 이유는 런타임 에러를 제거해주는 컴파일러 덕분이다. 메모리 안정성과 성능 및 편의성에 중점을 둔 언어로, 가비지 컬렉터 없이 메..
 Redis란?
Redis란?
last update : 2024-08-16개요Key, Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈소스 기반 비관계형 데이터베이스 관리 시스템(DBMS) 이다. 데이터베이스, 캐시, 메시지 브로커로 사용되며 인메모리 데이터 구조를 가졌다. Key, Value 저장소 중 가장 순위가 높다. 목적Q. 데이터베이스가 있는데도 Redis라는 인메모리 데이터 구조 저장소를 사용하는 이유는?A. 데이터베이스는 데이터를 물리 디스크에 직접 쓰기 때문에 서버가 다운되더라도 데이트가 손실되지 않지만, 매번 디스크에 접근해야 하기 때문에 사용자가 많아질수록 부하가 많아져서 느려질 수 있다. 초반에는 WEB-WAS-DB 구조로도 무리가 가지 않지만, 사용자가 많아질수록 DB 과부하 걸릴 확률이 높기 때문에..
 웹 브라우저가 메시지를 만든다 -1
웹 브라우저가 메시지를 만든다 -1
도서 : 성공과 실패를 결정하는 1%의 네트워크 원리 (링크)update : 2024-07-1001. HTTP 리퀘스트 메시지를 작성한다1. 여행은 URL 입력부터 시작한다.URL은 http:// 로 시작하는 것 뿐만 아니라 ftp: , file: , mailto: 등 다양한 종류가 있다. 브라우저는 웹 서버에 액세스하는 클라이언트로 사용하는 경우가 많지만, 브라우저에는 파일 i/o (FTP) 클라이언트, 메일 클라이언트 기능도 있다. 즉, 브라우저는 복합 클라이언트 소프트웨어이다.URL을 사용하는 법은 액세스 대상에 따라 다른데, 웹 서버나 FTP 서버에 액세스하는 경우 도메인 명이나 파일 경로를 URL에 포함시키고 메일의 경우 상대 메일 주소를 URL에 포함시킨다. 필요에 따라 사용자명, 패스워드, ..
 현대 네트워크 기초 이론 : 현대 네트워킹의 요소 -이더넷
현대 네트워크 기초 이론 : 현대 네트워킹의 요소 -이더넷
참고도서 : 현대 네트워크 기초 이론 최종 업데이트 : 2024-03-26 1.3 이더넷 이더넷 애플리케이션 이더넷은 대표적인 유선 네트워크 기술로, 최대 100Gbps의 높은 속도와 수km까지 지원하도록 발점함에 따라 서버와 대규모 데이터 저장장치에 사용하는 필수적인 기술이 됐다. 가정 내 이더넷 이더넷은 아직까지 거의 모든 가정용 네트워크 구성에 포함된다. 특히 전력선 통신 (PLC, Power Line Carrier) 과 이더넷 전원 장치(PoE, Power over Ethernet) 이 확장에 많은 기여를 했는데, 전력선 모뎀은 기존 전원선을 통신 채널로 사용해 전력 신호 위에 이더넷 패킷을 전송한다. PoE는 이더넷 데이터 이블로 전력을 공급한다. 사무실 내 이더넷 일반적인 사무실 환경에서 대부..
 현대 네트워크 기초 이론 : 현대 네트워킹의 요소 - 네트워크 생태계, 네트워크 아키텍처
현대 네트워크 기초 이론 : 현대 네트워킹의 요소 - 네트워크 생태계, 네트워크 아키텍처
참고도서 : 현대 네트워크 기초 이론 최종 업데이트 : 2024-03-25 1.1 네트워크 생태계 전체 네트워크 생태계의 존재 목적은 최종 사용자(end user)에게 서비스를 제공하기 위한 것이다. 사용자 플랫폼으로는 고정형, 휴대형, 모바일 모두 가능하며 사용자들은 네트워크 기반 서비스/콘텐츠에 네트워크 액세스 장비를 통해 접속한다. 예를 들면 와이파이, 셀룰러 모뎀, 디지털 가입자 회선 모뎀 등이 있으며 이러한 장비들을 통해 인터넷에 직접 연결하거나 공용 네트워크를 통해 네트워크 사업자와 연결한다. 애플리케이션 공급자는 사용자 플랫폼에서 실행되는 애플리케이션을 제공한다. 애플리케이션 서비스 공급자는 자신의 플랫폼에서 실행되는 애플리케이션 소프트웨어의 서버 또는 호스트 역할을 제공한다. 소프트웨어의 ..
 1장. 클라우드 네이티브란?
1장. 클라우드 네이티브란?
해당 포스팅은 오레일리의 책, 클라우드 아키텍트 트랜스포메이션을 보며 정리한 내용입니다. 최종 업데이트 : 2024-01-12 클라우드 네이티브는 단순한 도구 모음 이상의 의미가 있다. 완벽한 아키텍처로, 컴퓨팅을 최대한 활용하는 클라우드 애플리케이션을 구축하기 위한 철학적인 접근 방식이다. " 클라우드 네이티브"는 " 클라우드 " 가 아니다. 클라우드 컴퓨팅을 단순히 "클라우드"라 하면 인터넷을 통해 인프라스트럭처를 주문형 방식으로 제공하는 것을 의미한다. AWS, GCP, Azure 등의 클라우드 서비스 플랫폼에서 제공하는 경우가 많으므로 실제로 소비하는 자원에 대해서만 요금을 지불할 수 있다. 클라우드 네이티브는 위의 모든 클라우드 기반 구성요소를 클라우드 환경에 최적화된 방식으로 조립하기 위한 아..
 127.0.0.1과 localhost의 차이점은 뭘까?
127.0.0.1과 localhost의 차이점은 뭘까?
127.0.0.1과 localhost는 기본적으로 동일한 것을 가리키는데, 이들은 모두 로컬호스트를 나타낸다. 그러나 사용 목적에 따라 약간의 차이가 있을 수 있다. 좌측은 웹페이지에서 Localhost 접속 사진, 우측은 127.0.0.1 접속 사진이다. 127.0.0.1 - 127.0.0.1은 IPv4 주소 중 하나로, 로컬 루프백 (Loopback) 주소이며 네트워크에서 현재 시스템을 가리킨다. - 여기서 IPv4는 Internet Protocol version 4의 약어로 32비트로 구성되어 있어, 일반적으로 4개의 8비트로 표현된다. (127.0.0.1) - 이 주소는 TCP/IP 네트워크 스택에서 자체 테스트 및 통신을 위해 예약되어 있다. 즉, 네트워크 스택이 자체적으로 통신을 테스트하기 위..
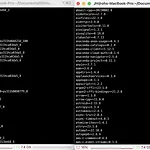 파이썬 패키지 requirements.txt - conda, pip
파이썬 패키지 requirements.txt - conda, pip
파이썬에서 환경을 설정할 때 패키지를 설치하고 실행하게 된다. 깃허브에 릴리즈된 수많은 오픈소스들을 봐도 보통 특정 프로젝트(코드)를 실행하기 위한 환경에 대한 정보가 제공되거나 requirements.txt가 함께 제공되는 것을 확인할 수 있다. requirements.txt 란? python 프로젝트 파일(.py)이 실행되는 데 필요한 패키지 정보들이 담긴 문서로, 다른 가상환경이나 다른 파이썬 환경에서 python 종속성을 따라 똑같은 환경을 구성할 수 있도록 도움을 준다. 이름을 꼭 requirements.txt로 네이밍할 필요는 없지만 대다수의 프로젝트에서 파이썬 패키지 리스트를 저장하는 파일을 requirements.txt 로 사용하고 있어 암묵적인 약속(?)의 네이밍이라고 생각하면 편하다. ..