
속도 < 방향
[CS50] 알고리즘 기초 : 시간 복잡도 본문
시간복잡도
앞서 배운 정렬을 진행할 때마다 시간이 소요되는데, 어떤 알고리즘을 수행하는 데 걸리는 시간을 시간복잡도라고 한다. 물리적인 시간이 아닌, 주어진 n개의 값을 활용하여 일반화한 복잡도를 의미한다. 일반적으로, 연산 횟수를 세며 이것이 측정 단위가 된다.
알고리즘을 수행할 때 걸리는 시간을 기준으로 효율성을 분석하는 것이다. 시간의 효율성이란 결국 알고리즘에서 비교와 교환 등이 일어날 때 연산자의 처리 횟수가 적다는 의미이며, 연산자의 처리 횟수가 적다는 건 시간의 복잡도가 낮다는 의미이다. 따라서 시간 복잡도가 낮을수록, 연산자의 사용 횟수가 적을수록 효율성이 높은 알고리즘이 된다.
예를 들어 버블 정렬이라면, 총 n개의 물체를 정렬할 때라고 가정하자.
첫번째 정렬을 할 때는 가장 큰 값이 가장 끝에 가므로 총 n-1번의 정렬을 시행하면 된다. 두번째에서는 n-2번, 세번째에서는 n-3번,.... 이런식으로 진행을 해서 마지막에는 1번 (가장 작은 것과 그 다음 작은 것) 만 시행하면 된다.
이를 수식으로 나타낸다면, $(n-1) + (n-2) + (n-3) + ... + 1$ 이다. 일반화하면 $n(n-1)/2$이다. $n^2$이 가장 큰 상수이며 뒤에 붙은 숫자는 $n^2$에 큰 영향을 미치지 않기 때문에 일반적으로 표현할 때 버블정렬의 시간복잡도는 $O(n^2)$이라고 한다.
시간복잡도를 표현할 때는 O() 라는 기호를 사용한다. 이를 Big-O 표기법이라고 한다. 버블 정렬 시행시간의 상한선이라고 봐도 무방하다. 즉, 최악의 경우를 의미한다.
O(n) 은 어떤 정렬일까? 가장 큰 수를 찾는 경우이다.
O(log n)은 전화번호부에서 특정 사람을 찾는 것과 같은 경우이다. 점점 작아지도록 반으로 나누는 것이다.
O(1) : random access 인데, 인덱스로 특정 인덱스에 접근하는 경우와 같다. 혹은 두 숫자를 더할때 연산은 한번만 이루어진다.
가장 최악의 경우가 big-O 였다면 가장 최선의 경우는 big Ω이다. 그리스 문자인 Omega(오메가)를 사용하는데 의미는 반대로, 알고리즘 실행 횟수의 하한선이다.
Ω(n) : 버블정렬을 포함한 대부분의 정렬은 Ω(n) 이 하한이다. 이미 정렬이 되어있는 경우일 것이다. Ω(n) 이 하한인 이유는최소한 n번은 비교해야 정렬이 됐는지, 안됐는지를 알 수 있기 때문이다.
Ω(1) : printf처럼 고정된 횟수가 필요한 경우이다.
big-O의 값과 big-Ω의 값이 같은 경우를 세타라고 의미한다.
선택정렬의 경우 $O(n^2)$ , Ω($n^2$)인데 가장 작은 수를 이미 찾았어도, 계속해서 더 작은 수를 찾으려고 하기 때문에 한번 수행 시 n개를 탐색해야 한다. 그래서 하한선도 $n^2$이 된다.
보고정렬: 무작위하게 섞고 정렬되었나 확인하는 것인데 이러한 정렬의 경우엔 최악의 경우 무한대가 될 수도 있다.
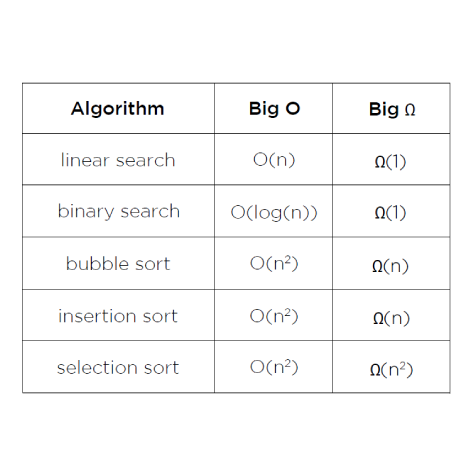
각 정렬을 big-O 시간복잡도와 big-Ω 시간복잡도로 나타내면 위와 같다.
'개발 > Computer Science' 카테고리의 다른 글
| [CS50] 합병 정렬, 이진 탐색 (0) | 2022.06.25 |
|---|---|
| [CS50] 알고리즘 기초 : 탐색, 정렬, 시간 복잡도 (0) | 2022.06.02 |
| [CS50] 알고리즘 (0) | 2022.04.09 |
| [CS50] 인공지능 (0) | 2022.04.09 |
| [CS50] 현실보다 더 생생한 세상 (0) | 2022.03.28 |



