
속도 < 방향
Bag of Tricks for Image Classification with Convolutional Neural Networks 논문 리뷰 summary 본문
Bag of Tricks for Image Classification with Convolutional Neural Networks 논문 리뷰 summary
import max 2021. 12. 23. 00:12[업데이트 : 2022-01-02]
논문 : Bag of Tricks for Image Classification with Convolutional Neural Networks
2019년에 발표된
Bag of Tricks for Image Classification with Convolutional Neural Networks
논문의 Summary 겸 리뷰를 적어보려고 합니다.
글을 쓰기에 앞서, 공부를 위해 논문을 보며 요약, 작성한 내용이라 간혹 오역이나 잘못된 내용이 있을 수 있습니다.
핵심 키워드는 highlight를 해두었습니다. 틀린 부분은 댓글로 알려주시면 감사하겠습니다^^
편의상 경어체를 빼고 작성하겠습니다.
Abstract
이미지 분류에서 최근 이뤄진 data augmentation이나 최적화같은 연구는 훈련 절차를 개선했다. 그러나 대부분 간단하게 언급되거나 소스코드에서만 볼 수 있다. 우리는 이 논문에서 해당 부분을 조사하고 깊게 연구하여 그들이 모델 정확도에 최종적으로 미치는 영향을 평가하려고 한다.
이러한 개선사항들을 결합하여 CNN 모델들을 개선할 수 있다. 예를 들어 ResNet50의 경우 75.3%의 정확도에서 79.29%로 개선되었으며, 이는 객체감지나 같은 작업 도메인에서는 더 나은 성능을 보여주기도 한다.
1. Introduction
2012년 AlexNet의 발견 이후 컨볼루션 신경망을 활용한 접근 방식이 지배적이었으며, VGG를 포함한 NiN, Inception, ResNet, DenseNet, NASNet등의 새로운 아키텍쳐들이 제안되었다.
이들은 성능 향상을 가져왔으며 이는 단순히 개선된 아키텍처로 인한 결과물이라기보다는 다양한 요소들도 함께 개선되었기 때문에 얻은 결과이다. (Loss Functions, Data Processing, Optimization Methods). 하지만 이들은 큰 주목을 받지 못해왔고 대부분은 아주 작은 수정이나 변경과 같은 '트릭'으로 보인다. 여러 네트워크를 사용하여 그들을 평가할 것이다.
Paper Outline
Section 2. 기본 훈련학습 절차
Section 3. 유용한 몇가지 트릭들
Section 4. 3가지 모델 아키텍처 조정 요소들
Section 5. 4가지 추가 절차 개선사항들
Section 6. 모델 전이학습
이 구현 모델과 스크립트들은 GluonCV 1에 공개되어있기 때문에 사용이 가능하다.
https://github.com/dmlc/gluon-cv
GitHub - dmlc/gluon-cv: Gluon CV Toolkit
Gluon CV Toolkit. Contribute to dmlc/gluon-cv development by creating an account on GitHub.
github.com
2. Traning Procedures

미니배치 경사하강법을 사용하여 훈련하는 템플릿이다. 각 iteration(반복) 에서 무작위로 b 이미지를 샘플링하여 기울기를 계산한다음 매개변수를 업데이트한다. K가 데이터셋을 통과한 후 중지된다.
2.1. Baseline Training Procedure
ResNet의 기본 파이프라인을 따른다.
2.2. Experiment Results
ResNet-50, InceptionV3, MobileNet의 세 가지 CNN을 평가할 것이며, 이미지는 299x299의 사이즈를 사용할 것이다. ISLVRC2012의 데이터셋을 사용하였다.
ResNet-50이 아주 근소한 차이로 가장 나은 결과를 보여줬으며 InceptionV3와 MobileNet은 다른 훈련절차로 인해 정확도가 약간 낮았다.
3. Efficient Training
하드웨어, 특히 GPU는 빠르게 발전하고 있으며 결과적으로 최근 몇 년동안 성능 관련 trade-off가 변경되었다. 예를 들어, 더 낮은 수치 정밀도와 더 큰 사이즈의 배치사이즈를 사용하는 것이 훈련에 더 효율적이다.
이번 섹션에서는 정확도를 낮추지 않으면서 대규모 배치 훈련을 가능하게 하는 기술들에 대해 검토한다.
3.1. Large-batch Training
미니배치 경사하강법은 병렬 처리의 성능을 높이고 커뮤니케이션에 따른 비용을 줄이기 위해 병렬 그룹화 한다. 하지만 사이즈가 큰 배치를 사용하면 속도가 느려질 수 있다.
볼록(convex)문제의 경우, 배치 크기가 증가함에 따라 수렴비율이 감소한다. 즉, 큰 배치로 훈련하는 모델은 작은 배치로 훈련한 모델보다 동일한 수의 epoch동안 정확도가 저하된다. 이를 해결하기 위해 휴리스틱을 제안한다. 총 4가지의 휴리스틱 방법을 제시할 것이다.
- Linear scaling learning rate
미니배치 경사하강법은 무작위 프로세스를 진행하고 있고, 배치 사이즈의 증가는 기울기의 기대치를 변경하지 않으면서 분산을 줄일 수 있다. 즉, 큰 배치는 기울기의 노이즈를 줄여주므로 학습률/학습속도(learning late)가 개선될 수 있다.
- Learning rate warmup
훈련 초기에는 매개변수들이 임의의 값이기 때문에 최종 솔루션에서 멀리 떨어져있다. 너무 빠른 학습률은 불안정성을 초래할 수 있다. 워밍업 단계에서는 처음에는 작은 학습률을 사용하고 훈련 단계에서는 다시 처음의 안정적인 학습률을 사용한다. 즉, 점진적으로 워밍업을 하며 학습률을 0에서 초기까지 증가시키는 선형 학습률을 사용한다.
- Zero γ
ResNet 여러 가지 잔여(residual) 블록으로 구성되어 있고, 각 블록은 여러개의 Convolutional Layer로 구성된다. 입력 x 가 주어질 때 출력값이 block(x)라고 가정하면, 마지막 레이어에서 잔여블록은 x+block(x)를 출력한다. 이 마지막 레이어는 배치 정규화 레이어(Batch Normalization Layer)가 된다. 각 요소들이 초기화되는 매개변수들이다.
따라서 모든 잔여 블록들은 인풋을 반환하고, 계층수가 적고 더 쉬운 네트워크가 초기 단계 훈련에서 훨씬 쉽다는 것을 확인할 수 있다.
- No bias decay
weight를 감소시키는 것은 모든 학습 가능한 가중치(weight)와 편향(bias)를 포함하는 매개변수에 적용된다. 모든 매개변수에 L2 정규화를 적용하여 값을 0으로 만드는 것과 같다. 하지만 과적합을 피하기 위해 가중치에만 정규화를 적용하는 것이 좋다.
3.2. Low-precision Training
신경망은 주로 32비트에서 훈련이 된다. FP32는 FP16 로 바꿨을 때 2-3배 정도 더 빨라진다(?). 기울기 범위를 FP16에 맞추는 것도 실용적이다.
3.3. Experiment Results

신경망
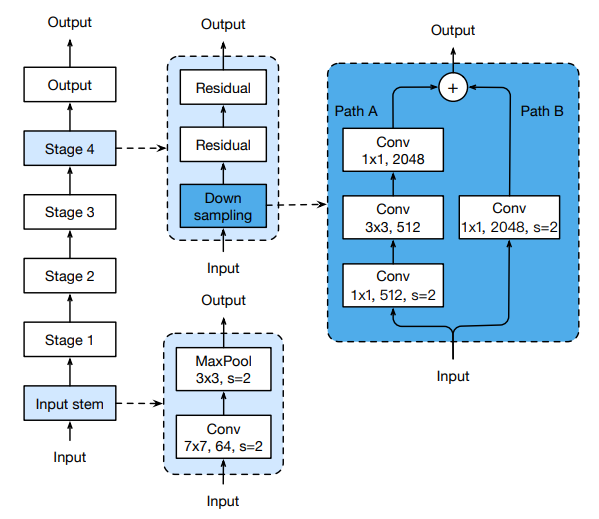
작성중(---ing )
7. Conclusion
논문에서는 모델의 정확도를 개선하기 위한 다양한 트릭들을 조사했다. 약간의 수정을 통해 ResNet-50, InceptionV3, MobileNet의 정확도가 개선됨을 확인하였다. 이 모든것을 함께 쌓으면 정확도가 훨씬 높아진다. 이번 연구를 통해 이를 통해 더 넓은 영역으로 확장될 수 있다고 믿으며 객체 탐지(Object detection) 분야나 분류(Segmentation) 분야에서는 큰 이점을 얻을 수 있을 것이다.


