
속도 < 방향
Recent Advances in Convolutional Neural networks 논문 리뷰와 Summary 본문
Recent Advances in Convolutional Neural networks 논문 리뷰와 Summary
import max 2022. 1. 2. 10:54[업데이트 : 2022-01-09]
논문 : Recent Advances in Convolutional Neural Networks
2015년에 발표된
Recent Advances in Convolutional Neural networks
논문의 Summary 겸 리뷰를 적어보려고 합니다.
글을 쓰기에 앞서, 공부를 위해 논문을 보며 요약, 작성한 내용이라 간혹 오역이나 잘못된 내용이 있을 수 있습니다.
핵심 키워드는 highlight를 해두었습니다. 틀린 부분은 댓글로 알려주시면 감사하겠습니다^^
편의상 경어체를 빼고 작성하겠습니다.
Abstract

그동안 nlp, vision 분야에서 딥러닝의 지속적인 발전이 있었고, 이는 컴퓨터 그래픽 프로세서의 발전뿐만 아니라 합성곱신경망의 발전 덕분이기도 하다. 이 논문에서는 CNN의 다양한 양상과 주요 요소들을 살펴보려고 한다.
Introduction

CNN은 시각피질세포가 빛을 감지하는 것에서 영감을 받아 개발한 인공신경망이다. CNN의 프레임워크를 기조로 손으로 쓴 문자(imagenet)를 분류할 수 있는 신경망을 개발했는데, 그것이 LeNet-5이다.
하지만, 그 당시에는 대규모 훈련데이터나 컴퓨팅 성능에 대한 부분이 부족했기 때문에, 대규모 이미지나 이미지 분류와 같은 복잡한 문제에서는 네트워크가 제대로 작동하지 않았다. 이러한 문제를 해결하기 위해 2006년 이후 많은 방법들이 개발되었고, deepCNN에서는 고전적인 CNN 아키텍처를 제안했다.
AlexNet은 LeNet-5와 비슷한 구조를 가졌지만 더 깊다. AlexNet이후 제안된 아키텍처들(ZFNet, VGGNet, GoogleNet, ResNet)을 살피면 네트워크가 더 깊어지는 추세이다. ResNet은 AlexNet보다 20배, VGGNet보다 8배 깊은데, 깊이를 증가시키면 더 나은 피처를 얻을 수 있다.


이 논문에서 다룰 구조들이다.
Section 2. CNN의 기본 구성요소 개요
Section 3. Convolutional Layer, Pooling Layer, Activation Function, Loss Function(손실함수), Regularization, Optimization
Section 4. 컴퓨팅기술
Section 5. Applications
Section 2. Basic CNN Components

CNN은 다양한 형태의 아키텍처가 있지만, 기본 구성 요소들은 거의 유사하다.
(LeNet-5를 예시를 들어서 설명하겠다.) Convolutional Layer, Pooling Layer, Full-Connected Layer 의 세가지 유형의 계층으로 구성된다.
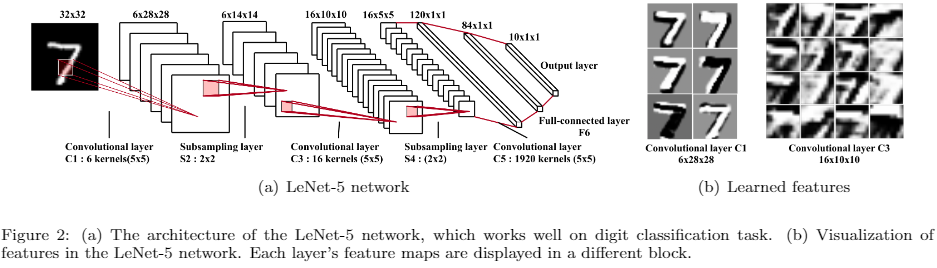
Convolutional Layer는 Input의 feature를 학습하는 것을 목표로 한다. 그림 2(a)에서 볼 수 있듯이 컨볼루션 레이어는 여러 가지 feature map을 계산하는 데 사용되는 여러 컨볼루션 커널로 구성된다. 이 feature map의 뉴런은 이전 layer의 뉴런 영역과 연결된다. 먼저 학습된 input을 Convolution한 후, 결과값을 Activation Function을 통해 Feature Map을 얻을 수 있다.

Activation Function(활성화함수)은 CNN에 비선형성을 도입하여, 다층 네트워크가 비선형 특징을 감지하는 데 적합하다. 일반적인 활성화함수는 sigmoid, tanh, ReLU등이 있다.
Pooling Layer는 Feature Map의 resolution을 줄여 shift-invariance를 달성하는 것을 목표로 하며, 일반적으로 두개의 Convolutional Layer 사이에 배치된다. 일반적인 Pooling Layer는 Average Pooling과 Max Pooling이 있다.
CNN의 마지막 레이어는 출력 레이어이다. 분류(classficiation) 작업의 경우, 일반적으로 softmax 연산자가 사용된다. θ는 CNN의 모든 매개변수를 나타낸다. 최적의 매개변수는 Loss Function(손실함수)를 최소화하여 얻을 수 있다. CNN 학습은 Optimization(최적화)의 문제이다. loss function를 최소화함으로써 최적의 매개변수 집합을 찾을 수 있다. SGD(경사하강법)은 CNN 네트워크 최적화를 위한 일반적인 솔루션이다.
Section 3. Improvements on CNNs

2012년 AlexNet의 성공 이후 많은 발전이 있었다. 그 개선점들을 여섯가지 측면에서 설명할 예정이다.
3.1. Convolutional Layer
컨볼루션 필터는 일반화 선형 모델이다. instance가 선형으로 분리할 수 있는 경우 추상화에 적합하다.
3.1.1. Tiled Convolution
Weight를 공유함으로써 매개변수의 수를 크게 줄일 수 있다. 이를 통해 동일한 레이어에서 별도의 커널을 학습하고, 인접 유닛에 대한 풀링을 통해 복잡한 불변성을 학습할 수 있다.

3.1.2 Transposed Convolution
Transposed Convolution은 전통적인 Convolutional Network의 역방향으로서 deconvolution이라는 용어를 사용하기도 한다. 그림3(d)에서 처럼 스트라이드와 패딩을 사용하여 4x4 입력에 대한 3x3 커널의 deconvolutional 연산을 볼 수 있다. 최근 visualization, 혹은 super-resolution, recognition, segmentaion 등의 분야에서 널리 사용되고 있다.
3.1.3 Dilated Convolution
이는 Convolution layer에 hyper-parameter를 추가한 것이다. 필터 요소 사이에 0을 삽임함으로써 receptive field의 크기를 늘리고 네트워크가 더 관련성 높은 정보를 다루도록 할 수 있다. 이는 예측할 때 큰 receptive field가 필요한 작업에 유용할 수 있다. 보통 기계번역, 음성합성/인식 분야에서 널리 사용된다.
3.1.4 Network In Network
Network In Network(NIN)은 선형 필터를 다층 퍼센트론 컨볼루션 레이어와 같은 네트워크로 대체하여, 보다 추상화에 용이하도록 한다. 최종 레이어의 feature map을 평균화하는 global average pooling을 적용하여 출력한 vector를 softmax레이어에 직접 공급한다. Fully-connected Layer와 비교했을 때, Global average Pooling은 매개변수가 훨씬 적기 때문에 과적합이나 계산 부하 부분에서 훨씬 자유롭다.
3.1.5 Inception Module
3.2 P
3.2.1 Lp Pooling
3.2.2 Mixed Pooling
3.2.3 Stochastic Pooling
3.2.4 Spectral Pooling
3.2.5 Spatial Pyramid Pooling
3.2.6 Multi-scale Orderless Pooling
3.3 A
3.3.1 ReLU
3.3.2 Leaky ReLU
3.3.3 Parametric ReLU
3.3.4 Randomized ReLU
3.3.5 ELU
3.3.6 Maxout
3.3.7 Probout
3.4 Loss
3.4.1 Hinge Loss
3.4.2 Softmax Loss
3.4.3 Contrastive Loss
3.4.4 Triplet Loss
3.4.5 Kullback-Leibler Divergence
3.5 Regularization
3.5.1 lp-norm Regularization
3.5.2 Dropout
3.5.3 DropConnect
3.6 Op
3.6.1 Data Augmentation
3.6.2 Weight Initialization
3.6.3 Stochastic Gradient Descent
3.6.4 Batch Normalization
3.6.5 Shortcut Connections
4. Fast Processing of CNN
4.1 FFT
4.2 Structured Transforms
4.3 Low Precision
4.4 Weight Compression
4.5 Sparse Convolution
5. Applications of CNNs
5.1 Image Classfication
5.2 Object Detection
5.3 Object Tracking
5.4 Pose Estimation
5.5 Text Detection and Recognition
5.5.1 Text Detection
5.5.2 Text Recognition
5.5.3 End-to-end Test Spotting
5.6 Visual Saliency Detection
5.7 Action Recognition
6. Conclusions and Outlook
CNN은 이미지, 비디오, 음성, 텍스트 등 다양한 형태의 데이터를 다루는 것에 있어서 중요한 역할을 했고, 그러한 작업들을 함에 있어 layer, activation function, loss function, optimization 등 중요한 개념들을 더 자세하게 다뤄야 한다는 점을 깨달았다.
하지만 여전히 해결해야 하는 문제들이 남아있다. 학습을 위해서는 대규모 데이터 셋과 뛰어난 컴퓨터 성능이 필요하다. 라벨링된 데이터를 수집하려면 많은 인력이 필요하기 때문에, CNN의 비지도 학습을 따르는 것이 바람직하다. 또한 SGD 알고리즘이 이미 합리적일지라도, 더 나은 계산 속도와 메모리를 위해 지속적으로 개발해야 한다.
학습률, 커널 크기, 레이어 수 같은 하이퍼파라미터를 적절하게 선택하는 것은 많은 기술과 경험이 필요할뿐더러 튜닝 비용이 많이 든다. 따라서, 학습을 위한 최적화 기술도 더욱 발전해야 할 것이다.



