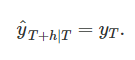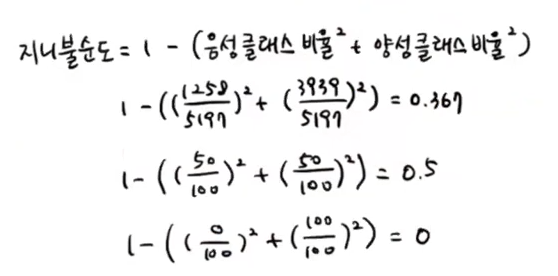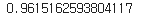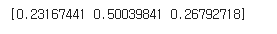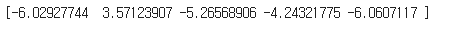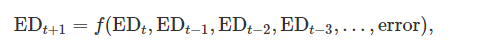과거 데이터가 전혀 없거나 완전히 새로우면서 독특한 시장 상황 등 특수한 상황에서 판단 예측 (judgmental forecasting) 을 사용할 수밖에 없다.
1) 이용할 수 없는 데이터가 없어 통계 기법을 적용할 수 없고 판단 예측으로만 접근이 가능한 경우 2) 이용할 수 있는 데이터가 있고 통계적인 예측값을 생성했고 판단을 이용하여 조정하는 경우| 3) 이용할 수 있는 데이터가 있고 통계적인 예측값과 판단 예측값을 독립적으로 내고 그 둘을 결합하는 경우
위와 같은 경우에 판단 예측을 사용할 수 있으며 일반적으로 통계적인 예측값은 판단만 이용하여 예측한 값보다 뛰어나다.
4.1 한계점에 주의하기
판단 예측값은 주관적이라 편견이나 한계점에 노출될 수밖에 없다. 사람의 인지력에 크게 의존하기 때문에 일관적이지 않을 수 있으며 인과 관계를 잘못 이해하거나 기억력 상실, 제한적 관심으로 인한 중요한 정보 소실 등의 결과가 발생할 수 있다. 또한 개인적이거나 정치적 쟁점때문에 예측값을 지나치게 극단적으로 설정하는 경우도 있다.
정착효과(the effect of anchoring) 도 흔히 나타나는데, 연이은 예측값이 초기 기준점과 비슷하거나 수렴하는 경향이 있다는 점이다. 흔히 마지막 관측치를 기점으로 두기 때문에 후행자가 선행 정보에 영향을 과도하게 받는 경향이 있다. 이러한 경향은 보수적인 생각을 낳아 현재에 더 가까운 정보를 과소평가하여 조직적인 편향을 생기게 한다.
4.2 핵심 원리
판단 예측을 할 때 체계적으로 접근하면 위의 한계점들을 해결하는 데 도움이 된다.
● 예측 작업을 간결하고 분명하게 정하기. 감정을 자극하는 용어나 상관없는 정보는 피하는 것이 좋다. ● 체계적인 접근 방식 구현하기. 관련 있는 요인들을 고려하고 정보에 가중치를 어떻게 줄지 확인해야 한다. ● 기록하고 정당화하기. 형식화하고 문서화하는 것은 반복 작업에 유리하며 일관성을 높일 수 있다. 편향성을 줄이는 데도 유용하다. ● 예측값을 체계적으로 평가하기. 체계적으로 관찰하면 뜻밖의 불규칙한 점을 찾아낼 수 있다. 꾸준히 기록하면 변하는 환경에 따라 대응하기도 좋기 때문에 추적 관찰하는 것이 좋다. ● 예측가와 사용자를 구분하기. 예측값을 사용할 사람이 예측 작업을 수행하는 경우에는 예측 정확도가 낮아질 수 없다. 잠재적인 사용자와 대화하는 것도 중요한데, 그렇지 않으면 사용자가 예측값을 신뢰하지 못할 수 있다. 또한, 경영진이 상향 예측에 대해 결정하는 경우 확증 편향이 발생할 수 있기 때문에 목표치를 정하는 것이 예측값을 내는 것과 다르다는 것을 분명히 하고 혼동해서는 안 된다.
위의 사례는 제약 혜택 제도인데, 회계 연도에서 의약품 양의 예측값을 낼 때 위와 같은 시계열 데이터 과정을 사용한다. 이 예측 과정을 통해 정부 예산을 정하는 데 도움을 얻을 수 있다. 새롭게 들어온 의약품과 그로 인한 예산안 또한 추정할 수 있다.
예측값을 낼 때는 모든 가정을 포함하여야 하며 각각의 경우에 대한 방법론이 모두 문서로 정리되어있어야 한다. 새로운 정책 예측값은 서로 다른 조직에 속한 최소 2명 이상의 사람이 같이 정해야 한다. 새로운 정책을 실행한 후 1년 뒤 검토 위원회가 예측값을 점검하고 유의미한 값이나 비용적으로 절감할 수 있는 부분에 대해 평가해야 한다.
4.3 델파이 기법
델파이 기법은 1950년대에 군사문제를 다루기 위해 개발된 기법으로 집단이 낸 예측값이 개인이 낸 예측치보다 더 정확하다는 핵심 가정에 의존한다. 기법의 목적은 구조화된 반복 이라는 방식을 통해 전문가 모임에서 얻은 합의로 예측값을 구성하는 것이다. 아래와 같은 순서로 진행된다.
1. 전문가들이 모여 예측 작업과 과제를 정하고 각 전문가에게 분담한다. 2. 각 전문가는 초기 예측값과 그를 뒷받침하는 근거를 공유한다. 3. 각 의견에 따른 피드백을 제공하고 피드백에 따라 다시 예측값을 검토하며, 이 작업을 합의가 이뤄질 때까지 반복한다. 4. 각 전문가의 예측값을 모아 최종 예측값을 구성한다.
전문가와 익명성
보통 5-20명 사이의 전문가로 모임을 구성하며, 가장 큰 특징은 전문가의 익명성이 항상 유지된다는 점이다. 이는 예측값을 낼 때 정치적/사회적 요인에 의해 영향을 받을 수 없다는 점이다. 모두에게 동등한 발언권이 주어지고 모두 같은 책임을 가지기 때문에 특정 구성원이 주도하거나 불참하는 상황을 막을 수 있다. 또한 지위나 사회적 관계에 의한 영향도 막을 수 있다. 비대면으로 진행하며 제출 기한에 맞춰 유연하게 일정을 진행할 수 있다.
델파이 기법에서 예측 작업 설정하기
예측 작업을 설정하기 전에 전문가 그룹을 통해 예비 정보 수집단계를 수행하는 것이 유용하다. 전문가 그룹이 초기에 제출한 예측값과 근거를 활용하여 여러 명의 정보를 취합한 다음 피드백에 활용할 수 있다.
피드백과 반복적인 예측
피드백을 진행할 때 전체적인 예측값에 대한 통계와 근거를 요약해야 한다. 또한 참여자(전문가)의 관심을 끌어야하기 때문에 전문적이 정보가 필요하다.
<예측값 제출, 피드백 수신, 예측값 검토>의 과정은 예측값을 모두 합의할 때까지 반복적으로 이루어진다. 합의가 만족스럽지 않더라도 응답의 다양성이 높아졌다면 어느 정도의 합의에 도달했다고 볼 수 있다. 너무 많은 반복은 참여자의 탈락을 유도할 수 있으므로 보통 2-3회 정도가 적당하다. 최종 예측값은 모두 같은 가중치를 주어 구성해야 하며 최종 예측값을 왜곡할 수 있는 극단적인 값을 염두에 두고 계산해야 한다.
델파이 기법이 아닌 '추정-대화-추정'을 사용하면 조금 더 간략하게 델파이 기법을 사용할 수 있지만 이의 단점은 아무리 익명성이 보장된다 하더라도 목소리가 과도하게 큰 사람의 의견이 영향을 줄 수 있다는 점이다.
4.4 유사점으로 예측하기
실제로 많이 사용되는 판단 접근 방식 중 하나가 유사점으로 예측하는 것인데, 예를 들어 주택 가격을 감정할 때, 해당 지역에서 판매된 비슷한 특징이 있는 집과 비교하는 것이다. 유사도는 어떤 속성(요인)을 고려하느냐에 따라 달라진다.
유사점으로 예측을 할 때는 한 가지 유사점보다는 여러가지의 유사점을 비교하여 근거한 예측값을 사용해야 한다. 속성의 갯수가 작을수록 편향이 생길 가능성이 없기 때문에 스케일링을 통해 비슷한 정도의 속성을 고려해야 한다. 유사점을 구조적으로 찾기 위해서는 델파이 기법과 유사한 단계로 접근할 수 있다. 여기서 익명성을 막는다면 협업을 막을 수 있기 때문에 핵심 전문가들의 익명성을 막지 않는다. 경험적으로 전문가들의 직접적인 경험을 통한 예측값이 가장 정확했다.
4.5 시나리오 예측
가능한 시나리오 목록에 기초하여 예측값을 내는 것이다. 앞서 이야기한 4-3과 4-4의 델파이기법, 유사점을 통한 예측값은 어느정도 가능한 결과값일 수 있지만 시나리오 기반 예측은 일어날 확률이 낮을 수 있다. 이는 모든 가능한 요인과 영향, 상호작용, 목표 등을 고려하여 생성하기 때문이다.
시나리오 에측은 넓은 범위의 예측값을 내고 극단적인 경우도 찾을 수 있다는 장점이 있다. 일반적으로 '최상', '보통'. ''최악' 의 3가지 경우로 시나리오를 생성하며 이렇게 극단적인 경우까지 생각해야 비상계획 수립으로 이루어질 수 있다.
4.6 신제품 예측
완전 새롭게 출시할 상품, 혹은 기성품에서의 약간의 개선, 새로운 시장으로의 진출 등 다양한 신제품이 있다. 하지만 이 모든 것은 과거의 데이터를 활용할 수 없기 때문에 보통 판단 예측이 유일한 방법으로 사용되는 편이다. 4-3, 4-4, 4-5에서 다룬 모든 방법이 수요 예측에 사용될 수 있다. 판매관리자(가장 고객과 가까운 위치)나 임원(가장 꼭대기)의 의견을 참고하여 예측값을 낼 수 있다. 판매관리자의 경우 고객의 불만을 가장 먼저 접하기 때문에 판단을 흐리게 할 수 있고, 임원은 기술적이나 자금적인 부분에 대한 정보가 있기 때문에 편향이 발생할 수 있다.
고객의 의도를 사용할 수도 있다. 설문지를 활용하여 제품을 구매하려는 의사가 있는 고객(잠재고객)에게 평가를 요청할 수 있다. 이를 위해서는 표본을 모으고 극단값에 대해 어떻게 처리할지를 미리 정해두는 것이 중요하다. 또한, 구매 의도가 실제 구매 행동으로 이루어지는지의 관계와 유사성을 염두에 두어야 한다.
앞서 말한 모든 것들은 데이터를 사용하는 평가지표가 될 수 있기 때문에 철저하게 문서화해야한다.
4.7 판단 조정
판단 예측을 할 때 과거 데이터를 활용하는 경우 실무자가 예측값에 대한 판단 조정을 할 수 있다. 이는 앞서 다룬 모든 기법에서의 장점을 가질 수 있지만, 만약 조건 자체가 false 인 경우라면 판단 조정 또한 흐려질 수 있다. 편향과 한계점이 따르기 때문에 그를 최소화하기 위한 방법론적 전략이 반드시 필요하다.
델파이 환경을 사용하면 장점이 있지만 그룹 회의에서 조정을 실패할 경우 참여자들의 의욕 저하가 일어날 수 있기 때문에 핵심 시장이나 상품의 예측값을 먼저 고려한 후 조정을 하는 방법을 선택하는 것이 나을 수 있다.
처음에 숫자 0 인줄 알았는데, 계속 에러가 나길래 봤더니 open 의 알파벳 O 였다...
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')
print(fruits.shape)
print(fruits[0, 0, :])
넘파이 배열의 데이터를 가져와서 첫 번째 행을 출력하면 위와 같은 리스트가 나오는 것을 볼 수 있다.
plt.imshow(fruits[0], cmap='gray')
plt.show()
imshow() 메소드를 사용하여 cmap 매개변수를 gray로 지정하여 흑백사진으로 이미지를 출력하여 볼 수 있다. 0에 가까울수록 검게 나타나고 높은 값을 밝게 표시된다. 이미지를 이렇게 반전시킨 이유는 우리의 관심사가 바탕이 아닌 물체(과일)에 있기 때문이다. 또한 우리가 바라보는 것과 컴퓨터가 이미지를 인식하고 처리하는 방식은 다르다는 것을 염두에 두어야 한다.
plt.imshow(fruits[0], cmap='gray_r')
plt.show()
cmap 매개변수를 gray_r로 지정하여 이미지를 재반전 후 출력하면 우리 눈에 좀 더 편한 이미지가 출력된다.
abs_mean은 각 샘플의 오차 평균이므로 크기가 300인 1차원 배열임을 알 수 있다.
apple_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
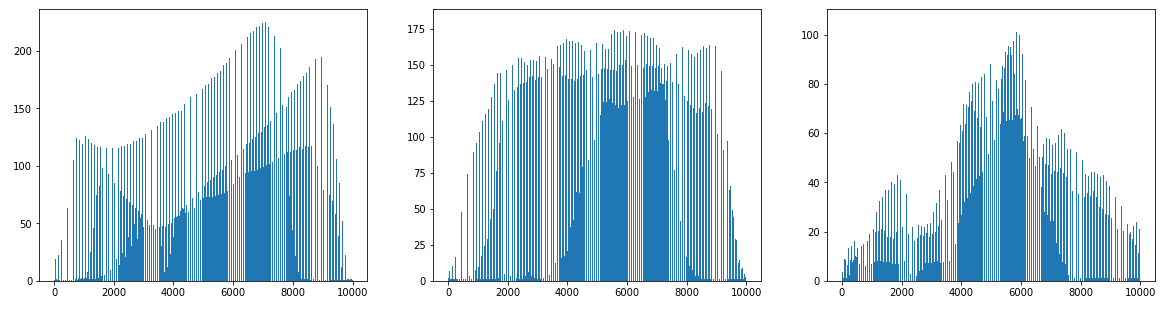
평균 값과 가장 오차가 적은 순서대로 이미지를 골라 10 x 10 배열로 출력한 결과다. axis() 매개변수를 'on'으로 설정하면 좌표값이 함께 출력된다. 여하튼, 이렇게 비슷한 샘플끼리 그룹으로 모으는 작업을 군집(clustering)이라고 한다. 군집은 대표적인 비지도 학습 작업 중 하나로, 군집 알고리즘에서 만든 그룹을 클러스터(cluster) 라고 한다.
06-2 k-평균
시작하기 전에
앞서 군집화를 할 때, 사과/파인애플/바나나 라는 것을 알고 있었지만, 실제 비지도 학습에서는 그러한 정보가 없이 진행된다. 이런 경우 k-평균(k-means) 군집 알고리즘을 통해 평균값을 자동으로 찾을 수 있다. 이 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심(cluster center) 또는 센트로이드(centeroid) 라고 부른다.
<k-평균 알고리즘>
# 기본미션
k-평균 알고리즘의 작동 방식은 아래와 같다.
무작위로 k개의 클러스터 중심을 정한다.
각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복한다.
알고리즘 작동 방식을 그림으로 그리면 위와 같다. 클러스터 중심을 랜덤하게 지정한 후 중심에서 가장 가까운 샘플을 하나의 샘플로 묶으면(1) 과일이 분류된 것을(2) 확인할 수 있다. 클러스터에는 순서나 번호는 의미가 없다. 여기서 클러스터 중심을 다시 계산한 다음 가장 가까운 샘플을 묶으면(2) 분류된 것을(3) 확인할 수 있다. 여기서 3의 결과와 2의 결과가 동일하므로 클러스터에 변동이 없다는 것을 캐치하고 k-평균 알고리즘을 종료하면 된다.
<KMeans 클래스>
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
print(km.labels_)
print(np.unique(km.labels_, return_counts=True))
k-평균 알고리즘은 KMeans() 클래스에 구현되어 있는데, n_clusters 매개변수를 활용하여 클러스터의 갯수를 지정해줄 수 있다. 주의할 점은, 비지도 학습이기 때문에 fit() 메서드에서 타깃 데이터를 사용하지 않는다는 점이다. 배열을 출력하여 샘플이 0, 1, 2 중 어떤 레이블에 해당되는지 확인하고 각 클러스터의 샘플의 갯수를 출력해 보았다.
def draw_fruits(arr, ratio=1):
n = len(arr)
rows = int(np.ceil(n/10))
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n:
axs[i, j].imshow(arr[i*10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_fruits() 함수를 만들고 레이블이 0인 과일 사진을 모두 그려볼 수 있다. 넘파이 자료형에서는 불리언 배열을 사용해 원소를 선택할 수 있고 이러한 것을 불리언 인덱싱(boolean indexing)이라고 한다. 더 자세한 내용은 4장에서 소개했었다. 즉, True인 원소만 추출하는 것이다.
레이블이 0인 클러스터는 파인애플이 다수이면서도, 사과와 바나나도 일부 섞인 것을 알 수 있다.
<클러스터 중심>
KMeans 클래스가 찾은 최종 중심은 cluster_centers_라는 속성에 저장되어 있다. 이 배열은 2d 이미지 샘플을 중심으로 이루어졌기 때문에 이미지로 출력하려면 100 x 100 크기로 다시 바꿔야 한다.
KMeans 클래스에서도 transform(), predict() 메서드가 있기 때문에 이를 활용하여 가장 가까운 클러스터 중심을 예측 클러스터로 출력하거나 예측할 수 있다. 또 n_iter_ 속성을 출력하여 반복횟수를 출력해볼 수 있다.
<최적의 k 찾기>
k-평균 알고리즘의 단점은 클러스터 개수를 사전에 지정해야 한다는 것이다. 적절한 k 값을 찾기 위한 몇 가지 도구가 있는데 엘보우(elbow) 방법이 대표적이다. k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있다. 이 거리의 합을 이너셔라고 하는데, 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값이다.
일반적으로 클러스터 개수가 늘어나면 클래스터 각각의 크기는 줄어들기 때문에 이너셔도 줄어든다. 엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 갯수를 찾는 방법이다.
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylavel('inertia')
plt.show()
이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있는데, 이 지점부터는 클러스터 개수를 늘려도 클러스터에 밀집된 정도가 크게 개선되지 않는다. 이 지점이 마치 팔꿈치 모양과도 같아서 엘보우 방법이라고 부른다고 한다.
06-3 주성분 분석
시작하기 전에 k-평균 알고리즘으로 나눠진 사진들을 군집이나 분류에 영향을 끼치지 않으면서 용량을 줄여서 저장할 방법이 없을까?
<차원과 차원 축소>
데이터가 가진 속성을 특성이라고 불렀는데, 머신 러닝에서는 이런 특성을 차원(dimension)이라 부른다. 앞서 다뤘던 과일 사진의 경우 10,000개의 픽셀 = 10,000개의 특성 = 10,000개의 차원이라는 뜻이다.
비지도 학습 작업 중 차원 축소(dimensionality reduction) 알고리즘이 있는데, 3장에서 차원이 많아지면 선형 모델의 성능이 높아지고 train model에 과적합 되기 쉽다는 것을 배웠다. 차원 축소는 데이터를 가장 잘 나타내는 특성을 선택하여 데이터의 크기를 줄이고 지도 학습 모델의 성능을 향상시킬 수 있는 방법이다.
대표적인 차원 축소 알고리즘인 주성분 분석(Principal Component Analysis)은 PCA라고도 부른다.
<주성분 분석 소개>
주성분 분석은 데이터에 있는 분산이 큰 방향을 찾는 것이다. 분산은 데이터가 널리 퍼져있는 정도를 말하는데, 분산이 큰 방향을 데이터로 잘 표현하는 벡터라고 생각할 수 있다.
위와 같은 2차원 벡터가 있을 때 대각선 방향이 분산이 가장 크다고 볼 수 있다. 이 벡터를 주성분(principatl component) 이라 부른다.
주성분 벡터의 원소 개수는 원본 데이터셋의 특성 개수와 같고, 주성분을 사용해 차원을 줄일 수 있다. S(4,2)를 주성분에 직각으로 투영하여 1차원 데이터 P(4,5)를 만들 수 있다. 주성분은 원본 차원과 같고 주성분으로 바꾼 데이터는 차원이 줄어든다.
첫번째 주성분을 찾고 이 벡터에 수직이고 분산이 가장 큰 다음 방향을 찾으면 두번째 주성분이 된다. 일반적으로 주성분은 원본 특성의 개수만큼 찾을 수 있다.
주성분 학습도 비지도 학습이기 때문에 fit() 메서드에 타깃값을 제공하지 않는다. 이 클래스가 찾은 주성분은 components_ 속성에 저장되어 있다. 이 배열의 크기를 확인해보니 n_components=50으로 지정했기 때문에 첫번째 차원이 50이고, 즉 50개의 주성분을 찾은 것을 알 수 있다. 두번째 주성분은 항상 원본 데이터의 특성 갯수인 10,000이다.
Rethinking on Multi-Stage Networks for Human Pose Estimation
논문의 Summary 겸 리뷰를 적어보려고 합니다.
글을 쓰기에 앞서, 공부를 위해 논문을 보며 요약, 작성한 내용이라 간혹 오역이나 잘못된 내용이 있을 수 있습니다.
핵심 키워드는 highlight를 해두었습니다. 틀린 부분은 댓글로 알려주시면 감사하겠습니다^^
편의상 경어체를 빼고 작성합니다.
시작하기 전에
내가 뽑은 키워드 : Pose estimation, bottleneck, 단일 단계 (single-stage) , 복합 단계 (multi-stage)
Abstract
포즈 추정(pose estimation)은 단일 단계 (single-stage) 와 복합 단계 (multi-stage) 방법으로 나뉘는데 복합 단계는 단일 단계만큼 성능이 좋지 않다. 이 연구에서는 MS COCO 와 MPII Human Pose 데이터셋을 활용하여 단일 단계 디자인, 교차 단계 기능 집합 및 지도 학습을 활용한 미세한 조정을 통해 성능을 개선하였다.
Introduction
최근 human pose estimation 분야는 심층 신경망 구조를 사용함으로써 빠른 성장을 해오고 있다. 좋은 성능을 보여주는 방법은 단일 단계 를 백본(back-bone) 네트워크로 사용하고 있다. 예를 들어 최근의 COCO (데이터셋을 활용한) 챌린지의 우승자는 Res-Inception 를 사용하였고 baseline은 ResNet 기반이다. pose estimation은 높은 공간 해상도를 요구하기 때문에 깊은 피처의 공간 해상도를 높이기 위해 백본 네트워크 뒤에 upsamling 또는 deconvolution 하는 과정이 추가된다.
또 다른 방법인 복합 단계 아키텍쳐의 경우 각 단계는 단순한 경량 네트워크이며 자체 다운 샘플링 및 업샘플링 경로를 포함한다. 단계 사이의 feature map (혹은 히트맵) 은 고해상도로 유지된다. 모든 단계는 미세한 지도학습 기반으로 이루어져 있으며, 겉보기에는 multi-stage가 pose estimation에 더 적합해 보인다. 고해상도를 가능하게 하고 더 유연하기 때문인데, 이는 데이터셋마다 다른 결과를 보여준다는 사실을 발견하였다.
이 연구에서는 위의 문제가 발생하는 것이 설계의 부족 때문이라고 지적하며 3가지 개선된 MSPN(Multi-stage Pose Estimationnetwork)을 제안한다. 첫째,복합 단계 방법의 단일 단계의 모듈이 좋지 않다는 사실을 발견하였다. 예를 들어 Hourglass의 모듈의 경우 모든 블록(업샘플링, 다운샘플링) 에 동일한 폭의 채널을 사용하는데 이것은 ResNet의 아키텍쳐와 완벽히 모순되는 내용이다. 대신에, 이미 존재하는 단일 단계 네트워크 구조 중 좋은 것(CPN사의 GlobalNet)을 발견하는 것만으로도 충분하다고 본다. 둘째, 위아래로 반복되는 샘플링때문에 정보가 손실될 가능성이 더 커지고 최적화가 더 어려워진다. 이를 해결하기 위해 여러 단계에 걸쳐 feature들을 종합할 것을 제안한다. 마지막으로, 복합 단계를 통해 pose localization 정확도(accuracy)가 개선되는 것을 관찰하며 미세한 지도학습을 적용한다.
Related work
최근의 pose estimation 연구 분야는 심층 신경망(DCNN) 을 사용하며 많은 발전이 있었고, 최근 연구 동향에 따르면 단일 단계와 복합 단계의 두 범주로 나누어서 접근해야 한다.
◆ Single-Stage Approch
단일 단계 접근 방법은 기본적으로 이미지 분류(image classsification) task 를 해결하기 위한 백본 네트워크로 이루어져있다. 이를테면 VGG, ResNet, Mask R-CNN, CPN(Cascade Pyramid Network) 등. 하지만 이들은 우수한 성능에도 불구하고 공통적으로 병목 현상(bottleneck)을 겪었는데, 단순히 모델 용량을 늘린다고 성능이 개선되지는 않는다는 것이다. 그림 1과 표 1을 통해 이를 확인할 수 있다.
◆ Multi-Stage Approch
복합 단계 접근 방법은 점점 더 정교한 추정을 목표로 하며 이는 상향식 (bottom-up) 방법과 하향식 (Top-down) 방법이 있다. 하지만 단일 단계 방법은 모두 하향식이다.
상향식 방법은 이미지의 개별 관절을 예측한 다음 이 관절을 사람의 instance에 연결한다. 예를 들어 VGG-19 네트워크를 feature encoder로 사용하고 출력 feature은 네트워크를 거쳐 heat map과 key point의 연관성을 생성할 수 있다.
하향식 방법은 먼저 detector를 통해 사람을 찾은 다음 핵심 포인트의 위치를 예측하고, 자세를 추정하기 위해 encoder로 심층 신경망을 사용한다. 이러한 복합 단계의 방법은 MPII 데이터 셋에선 잘 작동하지만 더 복잡한 COCO 데이터 셋에서는 경쟁력이 없다. 최근의 COCO 챌린지 우승자 또한 단일단계 기반의 단순 베이스라인 작업을 진행했고, 이 연구에서는 기존 복합 단계 아키텍처에 몇 가지를 수정하여 다단계(복합단계) 아키텍처가 훨씬 낫다는 것을 보여준다.
Multi-Stage Pose Network(MSPN)
이 연구에서는 두 단계로 하향식(top-down) 접근방식을 채택했는데, 첫번째 단계에서는 기성품인 human detector를 채택하였고, 두번째로는 MSPN을 바운딩 박스에 적용하여 결과를 생성하였다. MSPN은 3가지 개선사항을 제안한다. 먼저, 기존 단일 단계 모듈의 결함을 분석하고 최근(sota)의 단일단계 pose network가 쉽게 사용되는 이유를 설명한다. 다음으로, 정보 손실을 줄이기 위해 초기에서 후기 단계로 정보를 전파하며 기능을 수집하는 전랴을 제안한다. 마지막으로, coarse-to-fine (미세 감독) 지도학습의 사용법을 소개하며 localization 정확도에서 더욱더 세밀하게 적용할 수 있는 방법을 제안한다.
예측을 하는 데 있어 유용한 도구들과 예측 작업을 단순하게 만드는 법, 예측 기법에서 이용 가능한 정보를 적절하게 사용하게 사용했는지 확인하는 법, 예측구간(prediction interval)을 계산하는 기법 등을 살펴볼 것이다.
3.1 몇 가지 단순한 예측 기법
평균 기법
예측한 모든 미래의 값은 과거 데이터의 평균과 같다. 과거 데이터를 y1,…,yTy1,…,yT라고 쓴다면, 예측값을 다음과 같이 쓸 수 있다.
meanf(y, h)
# 시계열, 예측범위
단순 기법(naïve method)
단순 기법에서는 모든 예측값을 단순하게 마지막 값으로 둔다. 이 기법은 금융 시계열을 다룰 때 잘 들어맞는다.
naive(y, h)
rwf(y, h) # 위의 것과 같은 역할을 하는 함수
데이터가 확률보행(random walk) 패턴을 따를 때는 단순 기법(naïve method)이 최적이라서확률보행 예측값(random walk forecasts)이라고 부르기도 한다.
계절성 단순 기법(Seasonal naïve method)
계절성이 아주 뚜렷한 데이터를 다룰 때 비슷한 기법이 유용하다. 이 기법에서는 각 예측값을 연도의 같은 계절의(예를 들면, 이전 연도의 같은 달) 마지막 관측값으로 둔다. T+hT+h에 대한 예측을 식으로 쓰면,
m은 계절성의 주기(seasonal period), k=⌊(h−1)/m⌋+1k=⌊(h−1)/m⌋+1, ⌊u⌋⌊u⌋은 uu의 정수 부분을 나타낸다. 식으로 쓰니 실제 내용보다 복잡해 보이는데, 예를 들면 월별 데이터에서 미래의 모든 2월 값들의 예측값이 마지막으로 관측한 2월 값과 같다. 분기별 데이터에서, 미래의 모든 2분기 값의 예측치가 마지막으로 관측한 2분기 값과 같다. 다른 달과 분기, 다른 계절성 주기에 대해 같은 방식으로 적용할 수 있다.
표류 기법
단순 기법(naïve method)을 수정하여 예측값이 시간에 따라 증가하거나 감소하게 할 수 있다. 여기에서 (표류(drift)라고 부르는) 시간에 따른 변화량을 과거 데이터에 나타나는 평균 변화량으로 정한다. 그러면 T+hT+h 시간에 대한 예측값은 다음과 같이 주어진다.
처음과 마지막 관측값에 선을 긋고 이 선을 외삽(extrapolation)한 것과 같다.
rwf(y, h, drift=TRUE)
# Set training data from 1992 to 2007
beer2 <- window(ausbeer,start=1992,end=c(2007,4))
# Plot some forecasts
autoplot(beer2) +
autolayer(meanf(beer2, h=11),
series="평균", PI=FALSE) +
autolayer(naive(beer2, h=11),
series="단순", PI=FALSE) +
autolayer(snaive(beer2, h=11),
series="계절성 단순", PI=FALSE) +
ggtitle("분기별 맥주 생산량 예측값") +
xlab("연도") + ylab("단위: 백만 리터") +
guides(colour=guide_legend(title="예측"))
이런 단순한 기법이 가장 좋은 예측 기법이 될 수 있다. 하지만 대부분, 이러한 기법은 다른 기법보다는 벤치마크 역할을 할 것이다.
3.2 변환과 조정
과거 데이터를 조정하면 예측 작업이 더 쉬워진다. 여기에서 달력 조정, 인구 조정, 인플레이션 조정, 수학적 변환 등 이렇게 4종류의 조정 방식을 다룬다. 이러한 변환과 조정 방식을 사용하는 목적은 변동의 알려진 원인을 제거하거나 전체 데이터 모음에 걸친 패턴을 더 일관성 있게 만들어서 과거 데이터에 나타나는 패턴을 단순하게 만드는 것이다.
달력 조정
계절성 데이터에 나타나는 변동은 단순히 달력 때문일 수 있다. 이럴 땐, 예측 모델을 피팅하기 전에 변동을 제거해 볼 수 있다. monthdays() 함수로 각 월과 각 분기의 날짜를 계산할 수 있다.
월별 데이터와 일별 데이터를 비교해보면 일별 데이터가 더 단순한 것을 알 수 있다. 그 이유는 월 길이가 매월 다르다는 변동을 제거하고 일별 평균 생산량을 봤기 때문이다.
인구 조정
인구 변화에 영향을 받는 데이터를 1명당 데이터로 조정할 수 있다. 즉, 전체 대신에 1명당 데이터(또는 천명, 백만명)를 고려하는 것이다. 예를 들어, 어떤 특정 지역에서 시간에 따른 병원 침상 개수를 다루고 있다고 했을 때, 1,000명당 침상수를 고려하여 인구 변화 효과를 제거하면, 결과를 해석하기가 훨씬 더 쉬워진다. 그러면 침상 수가 정말로 증가했는지 여부나 증가량이 완전히 인구 증가에 따른 자연스러운 현상인지 여부를 확인할 수 있다. 전체 침상 수는 증가하지만 천명당 침상수는 감소할 수도 있다. 인구가 병원 침상수보다 빠르게 증가하면 이런 현상이 나타난다. 인구 변화에 영향을 받는 대부분의 데이터에서 전체보다 1명당 데이터를 다루는 것이 좋다.
인플레이션 조정
돈의 가치에 영향을 받는 데이터는 모델링에 앞서 적절하게 조정되어야 한다. 예를 들면, 인플레이션 때문에 이전 몇 십년 동안 새로운 집의 평균 가격이 증가했을 것이다. 올해 $200,000 가격의 집은 20년 전 $200,000 가격의 집과 같지 않다. 이러한 이유에서, 보통은 모든 값을 특정 연도의 달러 가치로 나타내도록 금융 시계열을 조정한다. 예를 들면, 주택 가격 데이터는 2000년대의 달러로 나타낼 수 있다. 이렇게 조정하기 위해, 가격 지수를 사용한다. 종종 정부 기관에서 가격 지수를 만든다. 소비재에 대해, 보통 가격 지수는 소비자 가격 지수(또는 CPI)다.
수학적 변환
데이터에서 시계열의 수준에 비례하여 증가/감소하는 변동이 보이면, 변환(transformation)이 유용할 수 있다. 예를 들면, 로그 변환(log transformation)이 유용하다. 로그의 밑을 10으로 사용하면, 로그 눈금에서 1만큼 증가하는 것이 원래의 눈금에서 10배 증가한 것과 대응된다. 로그 변환의 또 다른 장점은 원래의 눈금에 대해 예측치를 그대로 양수로 놓는다는 점이다.
제곱근(루트)과 세제곱근을 사용할 수 있다. 이것은 거듭곱 변환(power transformation)이라고 한다.
로그 변환과 거듭곱 변환을 둘 다 포함하는 유용한 변환은 박스-칵스(Box-Cox) 변환의 일종이다. 박스-칵스(Box-Cox) 변환은 매개변수 λλ에 따라 달라지고 다음과 같이 정의됩니다.
박스-칵스(Box-Cox) 변환에서 로그는 항상 자연 로그다. 그래서 λ=0이면, 자연 로그를 사용하지만, λ≠0이면, 거듭곱 변환(power transformation)을 사용한다. λ=1이면, wt=yt−1이라, 변환된 데이터에서 시계열의 모양 변화 없이 아래쪽으로 이동하게 된다. 하지만, 모든 다른 λ값에 대해서는, 시계열의 모양이 변할 것이다.
train_test_split() 메서드는 기본적으로 25%의 설정값으로 테스트 세트를 지정한다. 하지만 샘플 개수가 충분히 많다면 사이즈를 조절할 수 있다. test_size 매개변수를 활용하여 값을 지정할 수 있다. 5197개의 훈련, 1300개의 테스트 세트로 나뉘었다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.coef_, lr.intercept_)
표준정규화를 사용한 후 로지스틱 회귀모델을 훈련해 본 결과 77~78의 훈련 점수가 나왔다. 둘의 점수가 모두 낮으니 과소적합이 된 것으로 추정된다. 회귀가 학습한 계수와 절편값을 출력한 결과를 들여다보려고 한다.
<설명하기 쉬운 모델과 어려운 모델>
앞서 확인한 계수와 절편값을 설명하기에는 너무 어렵다. 이 모델이 왜 저런 계수 값을 학습했는지 '이해'한다기보다는 '추측'에 가까울 것 같다. 숫자로는 이해할 수 없기 때문에 순서도를 그리며 설명한다면 조금 더 이해도가 높아지지 않을까?
<결정 트리>
결정트리(Decision Tree) 모델이란 마치 스무고개처럼 하나씩 질문을 던져 정답을 맞춰가는 모델이다. 즉, 진실(True)과 거짓(False)을 통해 예/아니오로 질문을 이어가며 정답을 찾아 학습한다. 데이터를 잘 나눌 수 있는 질문을 찾는다면 질문을 추가해서 분류 정확도를 높일 수 있다. 사이킷런이 결정트리 알고리즘을 제공한다.
결정트리 알고리즘을 활용했더니 훨씬 점수가 높아졌다. 하지만 훈련세트에만 높은 점수로 미루어 보아 과대적합이 발생한 것으로 추측된다. 사이킷런의 메서드를 통해 이 모델을 그림으로 표현할 수 있다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
plot_tree() 메서드를 통해 트리를 그려볼 수 있다. 일반적으로 나무는 밑에서 위로 자라지만, 결정 트리는 위에서부터 아래로 탑다운(Top-down) 형태로 자란다. 맨 위의 파란색으로 동그라미한 노드를 루트 노드(root node)라 하고 화살표 모양으로 표시한 아래쪽에 주렁주렁 달린 노드를 리프 노드(leaf node)라고 한다.
회귀 모델의 경우 최종 도달한 리프 노드의 값의 평균이 새로운 샘플 x에 대한 예측값이라고 할 수 있다. 만약 분류 모델의 경우 k-최근접 이웃 알고리즘과 마찬가지로, 최종 조달한 라프 노드의 값 중 다수의 샘플들을 통해 예측할 수 있다.
노드란 결정 트리를 구성하는 핵심 요소로, 훈련 데이터의 특성에 대한 테스트를 표현한다. 하지만 이렇게 보기엔 복잡하니 트리의 깊이를 제한해서 출력할 수 있다.
max_features 매개변수를 통해 사용할 특성의 갯수를 지정할 수 있다. 기본값은 None이라 모든 값을 사용하게 되는 것이고, 만약 특성의 갯수보다 작다고 하면 random하게 특성을 선택한다.
plot_tree() 메서드를 사용하면 지정한만큼만 트리를 출력할 수 있다. max_depth 매개변수를 1로 준다면 루트 노트를 제외하고 추가적으로 하나의 노드를 더 확장하여 그린다. filled 매개변수는 클래스에 맞게 노드의 색을 칠할 수 있다. feature_names 매개변수에는 특성의 이름을 전달할 수 있다.
여기서 그림이 담고 있는 정보를 하나씩 살펴보면 루트노드는 당도가 -0.239 이하인지에 대해 묻는 것이고, 작거나 같으면 좌측, 크면 우측으로 이동하는 것이다. 그에 따라 이동한 sample은 루트노드의 5197개 샘플 중 좌측이 2922개, 우측이 2275개다. 또한 plot_tree() 함수에서filled=True로 지정하면 클래스마다 색상을 부여하고, 어떤 클래스의 비율이 높아지면 점점 진한 색으로 표현한다고 한다.
결정트리에서는 리프 노트에서 가장 많은 클래스가 예측 클래스가 되고 만약 여기서 트리의 성장을 멈춘다면 좌측 샘플과 우측 샘플 모두 양성 클래스의 갯수가 많기 때문에 모두 양성 클래스로 예측이 될 수 있다.
노드 상자안에 gini라는 것이 있는데 이것에 대해 좀 더 자세히 알아보려 한다.
<불순도>
gini는 지니 불순도를 의미한다. 불순도는 결정 트리가 최적의 질문을 찾기 위한 기준이다. DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값은 'gini'이다. criterion 매개변수는 노드에서 데이터를 분할할 기준을 정하는 것인데 앞서 당도 -0.239를 기준으로 나눈 것 또한 criterion 매개변수에 지정한 지니 불순도(Gini impurity)를 사용한 것이다.
지니 불순도는 클래스의 비율을 제곱해서 더한 다음 1에서 빼는 것이 계산 방법이다. 즉, 음성 클래스의 비율을 제곱한 것과 양성 클래스의 비율을 제곱한 것을 더해서 1에서 빼면 된다.
앞서 나뉜 샘플의 불순도를 계산하면 0.367이 나오고, 만약 정확히 절반씩 나뉜다면 0.5의 지니 불순도가 나타나는 것을 알 수 있다. 노드에 하나의 클래스만 있다면 지니 불순도는 0이 되고 이러한 노드를 순수노드라고 부른다.
부모의 불순도와 자식의 불순도를 뺐을 때 그 차이가 가장 크게 나오는 방향으로 노드를 분할하는 것이 결정트리의 방향이다. 이 불순도의 차이를 정보 이득(information gain)이라고 부른다. 하지만 사이킷런에서 제공하는 또 다른 불순도 기준이 있는데, criterion='entropy'를 지정하여 엔트로피 불순도를 사용할 수 있다. 이 불순도도 클래스 비율을 사용하지만 제곱이 아닌 밑이 2인 로그를 사용한다.
노드를 순수하게 나룰수록 정보 이득이 커지는데, 앞선 트리에서는 무한하게 자람에 따라 과대적합이 발생한 것을 알 수 있다.
<가지치기>
결정 트리도 무한하게 자라지 않도록 가지치기가 필요하다. 왜냐하면 과대적합이 발생할 수 있기 때문이다. 보통은 트리의 최대 깊이를 지정함으로써 설정이 가능하다.
맨 위의 루트노드가 깊이 0, 가장 밑의 리프노드가 깊이 3이다. 깊이 1의 노드는 모두 당도를 기준으로 훈련 세트를 나눈다. 하지만 깊이 2의 노드는 맨 왼쪽만 당도(sugar)로 나누고, 왼쪽에서 두 번째 노드는 도수(alcohol)로 나누는 것을 알 수 있다. 오른쪽 두 노드는 pH를 기준으로 나눈다.
깊이 3의 노드 중 유일하게 붉은 빛을 내는 세 번째 노드만 음성 클래스가 더 많다. 이 노드에 도달해야만 레드 와인으로 인식을 하고, 조건은 알코올 도수가 0.454보다 작으며 당도는 -0.802와 -0.239 사이어야 한다.
하지만 당도가 음수로 된 것이 좀 이상하다... 결정 트리 알고리즘의 장점은 특성값의 스케일이 알고리즘에 영향을 미치지 않는다는 점이다. 따라서 표준화 전처리를 할 필요가 없다.
트리를 그려보면, 특성값을 표준점수로 바꾸지 않아 훨씬 이해하기 쉽다. 즉, 당도가 1.625 와 4.325 사이에 있으면서 알코올 도수가 11.025 와 같거나 작은 것이 레드 와인이고 그 외에는 전부 화이트 와인임을 알 수 있다.
결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산해준다.
결정 트리 모델의 feature_importances_ 속성을 통해, 두번째 속성인 당도가 0.87 정도로 특성 중요도가 높은 것을 알 수 있다. 이들을 모두 더하면 1이 된다. 특성 중요도는 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산한다. 이를 활용하면 결정 트리 모델을 특성 선택에 활용할 수 있다.
# 기본미션
결정트리 예시
05-2 교차 검증과 그리드 서치
시작하기 전에
max_depth를 바꾸면 성능의 변화가 있지 않을까? 또 일반화 성능을 올바르게 예측하려면 테스트 세트로 만들어서 테스트 세트로 평가하면 안 되지 않을까?
<검증 세트>
테스트 세트를 사용하지 않으면 모델의 과대/과소 적합 여부를 판단할 수 없다. 테스트 세트를 사용하지 않고 측정하는 법은 훈련 세트를 또 나누는 것이다. 이 데이터를 검증 세트(validation set)라고 부른다.
데이터를 읽어와서 테스트와 훈련 세트로 나누고 다시 훈련세트와 검증세트로 나눈다. test_size 매개변수를 0.2로 지정하여 train_input의 약 20%를 val_input으로 만들고 크기를 확인해보면 훈련 세트가 4,157개, 검증 세트가 1,040개로 나눠진 것을 확인할 수 있다.
검증 세트를 너무 조금 떼어 놓으면 점수가 들쭉날쭉하고 불안정하다. 이럴 때 교차 검증(cross validation)을 이용하면 더욱 안정적인 점수를 얻고 더 많은 데이터를 사용할 수 있다. 교차 검증은 검증 세트를 떼어 평가하는 과정을 여러번 반복한다. 그 다음 이 점수를 평균하여 최종 검증 점수를 얻는다.
위의 그림은 3-폴드 교차 검증인데 훈련 세트를 세 부분으로 나눠서 교차 검증을 수행하는 것을 3-폴드 교차 검증이라고 한다. 통칭 k-fold 교차 검증(k-fold cross validation)이라고 하며, 훈련 세트를 몇 부분으로 나누냐에 따라 다르게 부른다.
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
cross_validate() 메서드를 통해 평가할 모델 객체를 매개변수로 전달한다. 이 함수는 딕셔너리를 반환하고, 처음 2개의 키는 각각 모델을 훈련하는 시간과 검증하는 시간을 의미한다. 각 키마다 5개의 숫자가 담겨 있고 기본적으로 5-폴드 교차 검증을 수행한다.
import numpy as np
print(np.mean(scores['test_score']))
교차 검증을 통해 입력한 모델에서 얻을 수 있는 최상의 검증 점수를 가늠해 볼 수 있다. 하지만 cross_validate() 함수는 훈련 세트를 섞어 폴드를 나누지 않기 때문에 만약 교차 검증을 할 때 훈련 세트를 섞으려면 분할기(splitter)를 지정해야 한다.
KFold 클래스도 동일하게 사용할 수 있다. n_splits 매개변수는 몇 폴드 교차 검증을 할지 정한다.
<하이퍼파라미터 튜닝>
모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터를 하이퍼파라미터라고 한다. 이것을 튜닝하는 작업은 먼저 라이브러리가 제공하는 기본값을 사용해 훈련을 한 다음 검증 세트의 점수나 교차 검증을 통해 조금씩 바꾸는 순서로 진행된다. 보통 모델은 최소 1-2개에서 5-6개까지의 매개변수를 제공한다.
결정 트리 모델에서 최적의 max_depth 값을 찾았을 때, 값을 고정하고 min_samples_split을 바꿔가며 최적의 값을 찾는 과정이 하이퍼파라미터 튜닝이 아니다. 왜냐하면 min_samples_split 매개변수의 값이 바뀌면 max_depth 의 값이 바뀌기 때문이다. 따라서 두 매개변수를 동시에 바꿔가며 최적의 값을 찾아야 한다.
매개변수가 많아질수록 문제는 더 복잡해지는데, 사이킷런에서 제공하는 그리드 서치(Grid Search)를 사용하면 편리하게 구현할 수 있다.
fit() 메서드를 통해 결정트리 모델의 min_samples_split 값을 바꿔가며 실행했다. GridSearchCV의 cv 매개변수 기본값은 5이다. 값마다 5-폴드 교차 검증을 수행하기 때문에 결국 25개의 모델을 훈련하는 것이다. 이처럼 많은 모델을 훈련하기 때문에 n_jobs 매개변수로 CPU 코어수를 지정할 수 있다. 기본값은 1이고 -1로 지정하면 모든 코어를 사용한다. 그리드 서치로 찾은 최적의 매개변수는 best_params_ 속성에 저장되어 있다.
0.001이 가장 좋은 값으로 선택된 것을 알 수 있다. 또한 두번째 list에서는 첫번째 값이 가장 크다. argmax() 함수를 통해 가장 큰 값의 인덱스를 추출할 수 있고, 인덱스를 활용해 params 키에 저장된 매개변수를 출력할 수 있다. 이 값이 앞서 출력한 gs.best_params_ 와 동일한지 확인해보면 같은 것을 알 수 있다.
이 과정을 정리해보자면 다음과 같다.
1. 탐색할 매개변수를 지정한다.
2. 훈련 세트에서 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾는다. 이 조합은 그리드 서치 객체에 저장된다.
3. 그리드 서치는 최상의 매개변수에서 전체 훈련 세트를 사용하여 최종 모델을 훈련하다. 이 모델 또한 그리드 서치 객체에 저장된다.
arange() 함수는 첫 매개변수 값에서 시작하여 두 번째 매개변수에 도달할 때까지 세 번째 매개변수를 계속 더한 배열을만든다. 0.0001에서 시작하여 0.001씩 더해서 0.001이 되도록 만드는 것이다. range() 함수는 정수만 사용할 수 있는데, max_depth 를 5에서 20까지 1씩 증가시킨다. min_samples_split 은 2에서 100까지 10씩 증가시키는 것을 알 수 있다. 9개 * 15개 * 10개 이므로 총 1,350번의 교차 검증횟수가 진행되며 5-폴드가 기본이므로 6,750개의 모델이 수행된다.
최상의 교차검증 점수를 확인해보니 이러한 값이 나왔다.
<랜덤 서치>
매개변수의 범위나 간격을 미리 정하기 어렵거나 너무 많은 매개변수가 있을 때 그리드 서치 시간이 오래 걸린다. 그럴 때 랜덤 서치(Random Search)를 사용하면 좋다. 랜덤 서치에는 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달한다.
이를 위해선 싸이파이(scipy) 라이브러리를 불러와야하는데 사이킷런에서는 넘파이와 사이파이를 많이 사용한다.
from scipy.stats import uniform, randint
rgen = randint(0, 10)
rgen.rvs(10)
uniform, randint 클래스는 주어진 범위에서 균등하게 값을 뽑는다(샘플링한다). randint() 는 정숫값을 뽑고, uniform() 은 실숫값을 뽑는다.
np.unique(rgen.rvs(1000), return_counts=True)
ugen = uniform(0, 1)
ugen.rvs(10)
난수 발생기와 유사한 원리로 이루어진다. 샘플링 횟수는 최대한 크게 하는 것이 좋다. 왜냐하면 샘플링 횟수가 많을수록 최적의 매개변수를 찾을 확률도 높아지기 때문이다.
0.00001에서 0.001 사이의 실숫값을 샘플링하여 매개변수에 지정한다. 매개변수를 다시 100번 샘플링하여 교차 검증을 수행한 후 최적의 매개변수 조합을 찾아 출력하면 위와 같은 결과가 나온다.
테스트 세트의 성능을 확인하면 검증 세트에 대한 점수보다 조금 작은 것이 일반적이다. 앞으로 수동으로 매개변수를 바꾸는 대신에, 훨씬 쉽게 파라미터를 조절할 수 있게 되었다.
05-3 트리의 앙상블
<정형 데이터와 비정형 데이터>
데이터를 나눌 때 보통 정형 데이터와 비정형 데이터로 많이 나누는데, 정형 데이터(structured data)는 csv파일처럼 excel, db 등 정형화 플랫폼에 저장할 수 있는 데이터를 말한다. 행과 열이 잘 구분되는 나열된 데이터들이다. 보통 대부분의 데이터가 정형 데이터다. 하지만 정형화되지 않은 데이터도 존재하는데, 데이터베이스나 엑셀로 표현하기 어려운 텍스트 데이터, 이미지, 음악 등의 데이터들을 비정형 데이터(unstructured data)라고 부른다.
정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습이다. 앙상블 알고리즘은 대부분 결정 트리를 기반으로 만들어졌다. 비정형 데이터를 다루기 위해서는 신경망 알고리즘을 많이 사용한다.
<랜덤 포레스트>
랜덤 포레스트(Random Forest)는 앙상블 학습의 대표 주자로 안정적인 성능 덕분에 널리 사용되고 있다. 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만들고 각 트리의 예측을 사용해 최종 예측을 만드는 것이다.
예를 들어 1,000개의 가방에서 100개씩 샘플을 뽑는다면 먼저 1개를 뽑고, 뽑았던 1개를 다시 가방에 넣는다. 이런 과정으로 샘플링을 진행한다면 중복된 샘플을 뽑을 수 있다. 이렇게 만들어진 샘플을 부트스트랩 샘플(bootstrap sample)이라고 부른다. 보통 중복을 허용하여 데이터를 샘플링하는 방식을 의미한다.
사이킷런의 랜덤포레스트는 기본적으로 100개의 결정트리를 이러한 방식으로 훈련한다. 랜덤하게 선택하기 때문에 훈련 세트에 과대적합되는 것을 막아주고 안정적인 성능을 얻을 수 있다.
# 선택미션
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
cross_validate() 함수를 사용해 교차 검증을 하고 모든 CPU 코어를 사용한 다음 출력 결과를 보면 다소 훈련 세트에 과대적합된 것을 알 수 있다. 랜덤 포레스트는 결정트리의 앙상블이기 때문에 결정트리 클래스가 제공하는 모든 매개변수를 제공한다.
데이터 분석 작업에서 가장 먼저, 많이 하는 것이 데이터 시각화다. 그래프를 통해 패턴, 관측값, 변수에 따른 변화, 변수 사이의 관계 등 데이터의 많은 특성을 파악할 수 있다. 데이터 시각화 과정은 예측 기법에 반드시 포함되어야 한다.
2.1 ts객체
시계열이란 각 숫자가 기록된 시간에 관한 정보가 있는 숫자들의 목록이다. R에서는 이러한 정보를 ts 객체로 저장할 수 있다.
y <- ts(c(123,39,78,52,110), start = 2012)
위와 같은 관측값의 데이터를 활용하여 예측할 때는, ts() 메서드를 활용하여 ts 객체로 바꿀 수 있다.
y <- ts(z, start = 2003, frequency = 12)
만약 자주 관측된 값의 경우라면 단순하게 frequency 입력값만 추가하면 된다. 월별 데이터가 수치 벡터 z에 저장되어 있는 것 또한 ts 객체로 바꿀 수 있다.
시계열의 빈도
빈도(frequency) 는 특정 구간의 패턴(계절성)이 반복되기 전까지의 관측값의 수를 의미한다. 물리학이나 푸리에(Fourier) 분석에서는 이것을 '주기(period)'라고 부른다.
실제로 1년은 52주가 아니고 윤년이 있기 때문에 평균적으로 52.18 주임을 알 수 있다. 하지만 ts() 객체는 입력값이 정수여야 한다. 관측값의 빈도가 주 1회 이상일 때는 주간/연간/시간별/일별 등 다양한 기간 동안의 계절성이 있을텐데 그 중 어떤 항목이 중요도가 높은지에 따라 결정해야 할 것이다.
2.2 시간 그래프
시계열 데이터에서 가장 먼저 그려야 할 요소는 시간 그래프(time plot) 이다. 즉, 관측값을 관측 시간에 따라 인접한 관측값을 직선으로 연결하여 그리는 것이다.
autoplot() 메소드를 활용해 그래프를 그릴 수 있다. 미래 승객수를 예측하기 위해 위의 그래프에서 발견할 수 있는 특징 전부를 모델링에서 고려해야 한다.
autoplot(a10) +
ggtitle("Antidiabetic drug sales") +
ylab("$ Millionr") +
xlab("Year")
당뇨병 약의 매출을 확인했는데, 시계열의 수준이 증가함에 따라 계절성 패턴의 크기 또한 증가하는 것을 알 수 있다. 또한 연초마다 매출이 급감하는 이유는 정부의 보조금 정책 때문이다. 이 시계열을 활용한 예측에서는 위의 계절성 패턴과 더불어 변화의 추세가 느리다는 사실을 예측치 안에도 담아내야 한다.
2.3 시계열 패턴
● 추세(trend) : 데이터가 장기적으로 증가/감소할 때 존재하는 패턴이나 방향성. 추세는 선형적일 필요는 없다. 예를 들어 추세가 '증가'에서 '감소'로 변할 때, '추세의 방향이 변했다' 라고 언급할 수 있다.
● 계절성(seasonality) : 해마다 어떤 특정한 때나 1주일마다 특정 요일에 나타나는 등의 요인. 보통 빈도의 형태로 나타나는데, 그 빈도는 항상 일정하다.
● 주기성(cycle) : 고정된 빈도 가 아닌 형태로 증가나 감소하는 모습을 보일 때 주기(cycle)가 나타난다. 보통 경제 상황이나 '경기 순환(business cycle)' 때문에 일어나는 경우가 있다. 이런 변동성의 지속기간은 적어도 2년 이상 나타난다.
많은 사람들이 주기성(cycle)과 계절적인 패턴(seasonality)을 혼동하지만 둘은 굉장히 다르다. 일정하지 않다면 주기성이고, 빈도가 일정하고 특정 시기와 연관이 있다면 계절성이다. 일반적으로 주기성은 계절성의 패턴보다 길고 변동성도 큰 편이다.
2.4 계절성 그래프
● 계절성 그래프는 각 계절에 대해 관측한 데이터를 나타낸다는 점을 제외하고 시간 그래프와 비슷하다.
seasonplot() 을 사용하면 계절적인 변동이 있는 데이터를 그리기에 좋다. seasonplot은 forecast 패키지에 들어있기 때문에 libarary(forecast)를 통해 먼저 설치를 하고 메서드를 실행하면 아래와 같은 그래표를 확인할 수 있다.
2.2 에서 다뤘던 데이터와 같은 데이터지만 데이터를 계절별로 포개며 나타내고 있다. 중요한 계절성 패턴을 시각적으로 분명하게 보여주고 있다. 특히, 매년 1월에 매출이 크게 뛰는데, 소비자들이 연말에 당뇨병 약을 사재기하는 모습과 2008년 3월의 경기 침체로 매출이 굉장히 작았던 모습을 알 수 있다.
분기별 맥주 생산량에 대한 시차 산점도이다. window() 메서드는 시계열의 부분을 뽑아내는 함수이다.
가로축은 시계열의 시차값(lagged value)를 나타낸다. 그래프는 서로 다른 k값에 대하여 세로축을 가로축에 대해 나타낸 것이다. 세로축의 색상은 분기별 변수를 나타낸다. lag 4, lag 8에서 발견할 수 있는 양의 관계는 데이터에 강한 계절성이 있다는 것을 반영한다. lag 2, lag 6 에서는 음의 관계가 나타난다.
2.8 자기상관
상관값이 두 변수 사이의 선형 관계의 크기를 측정하는 것처럼, 자기상관(autocorrelation)은 시계열의 시차 값(lagged value) 사이의 선형 관계를 측정한다.
여기서 T는 시계열의 길이이다.
이 값은 산점도와 대응대는 자기상관계수인데, 보통 자기상관함수(ACF)를 나타나기 위해 필요한 값이다.
ggAcf(beer2)
파란 점선은 상관계수가 0과 유의하게 다른지 아닌지를 나타낸다.
ACF 그래프에서 추세와 계절성
데이터에 추세가 존재할 때, 작은 크기의 시차에 대한 자기상관은 큰 양의 값을 갖는 경향이 있는데, 시간적으로 가까운 관측치들이 관측값의 크기에 있어서도 비슷하기 때문이다. 그래서 추세가 있는 시계열의 ACF는 양의 값을 갖는 경향이 크며, 이러한 ACF의 값은 시차가 증가함에 따라 서서히 감소한다.
CPU의 용량은 굉장히 제한적이라서 1MB정도의 저장공간만 있다. 한 번에 64bit정도만 처리하면 되기 때문이다. CPU가 두 수를 더한다면 64bit + 64bit 이기 때문에 파일 크기와 관계 없이 적은 양만 CPU로 가져온다. 계산을 하는 동안 데이터를 다른 곳에 저장하는데, 그것을 저장하는 곳이 바로 RAM이다.
RAM은 임의 접근 기억장치다. 메모리는 두 가지 종류가 있는데, RAM과 하드디스크가 있다. 두 메모리는 반대의 성질을 띄는데, 하드디스크는 영구적이고 휘발성이 없는데 반해 RAM은 일시적이고 전원을 끄면 사라지기 때문에 휘발성이 있다. 보통 파일이나 프로그램을 더블클릭하면 도달하는 곳이 RAM이다. 문서를 작성하거나 프로그램을 실행할 때 자료나 프로그램들은 하드디스크에 복사되고 RAM에 일시저장된다. RAM에 저장되는 이유는 하드디스크보다 빠르기 때문이다.
RAM이 더 빠른데도 불구하고 하드디스크를 보통 더 크게(많이) 가지고 있는 이유는 하드디스크에 있는 내용물을 동시에 볼 필요가 없기 때문이다. 우리가 동시에 하드디스크의 모든 프로그램을 실행하지는 않기 때문이다. 또한, CPU에는 어차피 병목현상이 있기 때문에 하드디스크의 용량과 무관하게 훨씬 좁은 파이프라인으로 데이터가 흘러 들어가게 된다.
RAM의 용량이 더 작은 이유는 비싸기도 하고 기술적으로 아직 많은 용량을 담을 수 없기 때문이다. RAM이 더 동적이라고도 말할 수 있는데, RAM이 여러가지를 한꺼번에 처리하는 반면에 하드디스크는 정적인 상태라고 말할 수 있다. 하지만 RAM과 하드디스크는 서로 상응하는 관계이기 때문에 계속해서 커질 것이다.
하드디스크에 있는 프로그램을 더블클릭하면 RAM에 적재되고 이 일이 발생하기 위해서는 컴퓨터가 입력장치(마우스,키보드)에 반응하기 위해 CPU로 비트가 흘러 들어간다. 메모리의 종류에는 L1,L2,L3 등의 캐시 종류가 있는데 L1은 1차, L2는 2차를 의미한다.
L1 캐시가 이 셋 중에서 가장 작고 빠르며, 중앙처리장치가 재빨리 받아 처리할 수 있도록 몇 킬로바이트의 데이터만을 저장한다. L2 캐시는 L1 캐시보다 조금 크지만, 그만큼 더 느리다. L3 캐시는 보통 몇 메가바이트를 저장할 수 있어 셋 중 가장 크지만 가장 느리다. 그래도 L3 캐시는 RAM보다는 빠르다.
CPU에 가까울수록 더 빨리 데이터를 받을 수 있지만 양이 적다. 기술적 효율성 때문에 이런 순서로 진행이 된다. CPU는 항상 할 일이 있고 비트를 계속 보낼 수 있기 때문에 빨라야 하고, CPU에서 멀어질수록 느려도 된다.
하드디스크가 크면 더 많은 것들을 저장할 수 있고, RAM이 크면 동시에 더 많은 일을 한꺼번에 수행할 수 있다. 사실 '동시에' 수행되지는 않지만 엄청나게 빠른 속도로 수행되기 때문에 동시에 수행되는 것처럼 느껴지는 것이다. CPU는 한번에 한가지 일밖에 처리할 수는 없지만 인간이 컴퓨터보다 상대적으로 느리기 때문이다.
요즘 운영체제에서는 '가상 기억장치'라는 것을 제공하는데 만약 500MB 정도의 작은 RAM에서 파일을 실행한다면 이 비트들을 RAM에서 하드디스크로 옮긴다. 프로그램을 실행시키기 위한 공간이 필요하기 때문이다. 그래서 우리가 어떠한 프로그램을 실행할 때 버벅거리거나 로딩이 오래걸린다면 그러한 가상 기억장치로의 이동작업이 이루어졌기 때문이다.
이렇게 버벅거리는 동안 하드디스크에 있던 프로그램을 다시 RAM으로 옮기고 RAM에 있던 프로그램을 다시 하드디스크로 옮기는 작업이 이루어진다. RAM이 크면 이러한 과정들이 생략되기 때문에, PC를 구매할 때 램(메모리)가 큰 것에 투자하는 것이 좋다. 물론 CPU나 디스크(하드) 크기가 큰 것도 좋지만 그래도 램이 우선순위가 높지 않을까?
L2, L1 캐시(Cache)는 CPU에 붙어 나오는데, 구매할 때 L2캐시가 많은 것을 구매할 수 있는 것이 아니다. 1.3GHz의 PC가 1.5GHz의 PC보다 빠를 수도 있는데, RAM이나 CPU의 캐시의 차이에 따라 달라질 수 있다.
우리가 pc를 구매할 때, 마케팅팀의 눈속임에 따라서 플로우가 흘러가게 된다. nn만원만 더 투자하면 훨씬 성능이 좋은 걸 사게 되도록 가격이 구성되어 있기 때문이다. 이런 눈속임에 홀리지 않고 정말 나에게 필요한 것이 무엇인지 알고 가격대가 합리적인지 캐치하기 위해서는 하드웨어에 대해 알아두면 좋다. 하드웨어는 컴퓨터를 물리적으로 구성하는 요소이며, 다양한 하드웨어의 기능과 차이점에 대하여 잘 알수록 유용하게 활용할 수 있다.
위와 같은 하드웨어가 있을 때 인텔 사의 cpu를 쓰고 속도는 3.2GHz 라는 것을 알 수 있다. FSB는 Front Side Bus의 줄임말로, 기억장치의 속도나 메인보드의 부품들의 속도를 볼 때 참고할 수 있다. 이는 중앙처리장치라고도 하는데, 입력 장치에서 받은 명령을 실제로 처리한다. CPU가 1초에 얼마나 많은 연산을 할 수 있는지 속도를 측정하는 단위는 기가헤르츠(GHz)다.
Operating system : Genuine Windows 10 Professional 64
위와 같은 운영체제가 적혀있는데 보통 크게 윈도우, MacOS, 리눅스 등의 운영체제가 있고 우리가 어느 나라에 가든 그 나라의 법을 따라야 하는데 운영체제에 따라 사용법이 다르다. 그래서 어떤 방식으로 컴퓨터를 운영할지에 대한 체계라고 생각하면 된다. 운영체제에는 32bit와 64bit가 있는데 같은 버전에서도 다른 bit가 있다. 요즘은 거의다 64bit이고 훨씬 빠르다. 하지만 32bit에서 만든 프로그램이 32bit 전용 프로그램이라면 64bit에서 실행하지 못할 수도 있다.
Display : 27.1 "WXGA LED Panel with Wide viewing Angle
디스플레이의 유형인 WXGA 등의 약어는 종류를 쉽게 구분하기 위해 사용하는 것이다.
Total memory : Crucial RAM 16GB DDR4 3200MHz CL22
Hard Drive : Seagate BarraCuda 1TB Internal Hard Drive HDD – 2.5 Inch SATA 6 Gb/s 5400 RPM 128MB Cache
16기가의 램 메모리와 1테라바이트의 하드디스크를 가지고 있는 것임을 알 수 있다.
기억장치는 입력된 명령이나 데이터가 저장되는 공간으로, 주기억장치와 보조기억장치로 나누어진다. 주기억장치에는 RAM이 있다. RAM은 기억된 정보를 읽어내기도 하고 다른 정보를 기억시킬 수 있는 메모리로서, 응용 프로그램을 일시적으로 불러오거나 데이터를 일시적으로 저장하는데 사용되는 임의 접근 기억 장치이다. RAM이 메모리에 얼마나 많은 양의 정보를 저장할 수 있는지 측정하는 단위는 보통 기가바이트(GB)가 사용된다.
하드드라이브(C:)는 영구적으로 데이터를 저장한다. 이런 하드드라이브를 보조기억장치라고 하는데, 많이 쓰이는 하드디스크(Hard Disk Drive, HDD)는 원판 모양의 플래터를 회전시켜 드라이브에 데이터를 읽고 쓰는 원리다. 하드드라이브는 다양한 용량이 존재하는데 보통 기가바이트(GB)나 테라바이트(TB) 단위가 쓰인다.
입력장치와 출력장치를 통틀어 입출력장치라고 부른다. 컴퓨터의 입력장치로는 마우스, 키보드, 스캐너 등이 있다. 입력장치는 사용자가 입력한 자료를 컴퓨터가 이해할 수 있는 형태로 변환하는 장치다. 컴퓨터의 출력장치로 대표적인 것은 모니터와 프린트를 들 수 있다. 흔히 모니터는 이야기 할 때 크기와 해상도와 크기를 언급하는데 모니터의 크기는 보통 대각선 끝과 끝의 길이를 인치로 표시한다.
해상도는 우리가 이미지를 볼 때 얼마나 선명하게 볼 수 있는가를 숫자로 나타낸다. 화면에 이미지를 확대해 보면 하나의 작은 점으로 나타나는데 이 하나의 작은 점을 픽셀이라고 한다. 즉 픽셀의 개수가 해상도가 된다. 픽셀의 개수가 많으면 많을수록 해상도는 높아지고 우리는 선명한 이미지를 볼 수 있다.
지난번 업로드했던 내용이 정리가 잘 되었는지 우수 혼공족으로 선정되었다. 항상 도움 많이받는 한빛미디어! 혼공족장님도 열일해주셔서 너무 감사하고,,백신 후유증은 괜찮으신가요? 사랑하는 한빛미디어 뼈를 묻겠습니다..♡
04. 다양한 분류 알고리즘
04-1 로지스틱 회귀
시작하기 전에럭키백을 판매한다고 할 때, 고객에게 힌트를 주기 위해 확률을 구하는 문제가 있다.
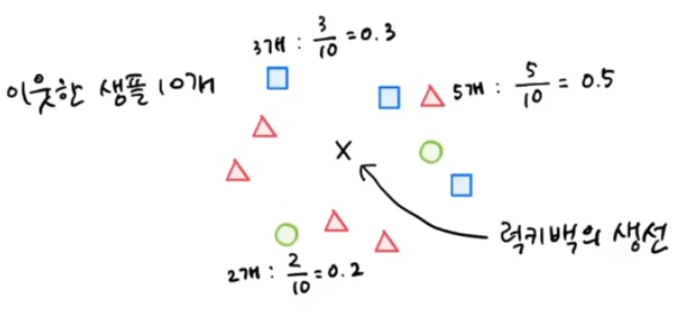
<럭키백의 확률>
k-최근접 이웃 분류기를 통해 생선의 확률을 계산할 것이다. 이웃한 샘플 중 다수의 항목들로 분류될 확률이 크다.
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()
판다스의 데이터프레임으로 데이터를 읽는다. head() 메서드는 처음 5개 행을 출력해준다. 첫번째 열만 타겟으로 만들고, 나머지 열을 특성으로 만들면 된다.
print(pd.unique(fish['Species']))
unique() 메서드를 통해 고유한 값을 추출해볼 수 있다.
# 여러 열 선택하여 넘파이배열로 바꿔 저장하기
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
print(fish_input[:5])
# 타깃 데이터 넘파이배열로 저장하기
fish_target = fish['Species'].to_numpy()
print(fish_target[:5])
넘파이배열을 통해 데이터를 쉽게 정리할 수 있다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
앞의 챕터에서 했던 것처럼 훈련 데이터와 테스트 데이터를 StandardScaler 클래스를 사용해 표준화 전처리해준다.
앞서 데이터 프레임을 만들 때 7개의 생선 종류가 들어있었기 때문에, 타깃 데이터에도 7개의 종류가 들어가 있다. 이렇게 타깃 데이터에 2개 이상의 클래스가 포함된 문제를 다중 분류(multi-class classification)라고 부른다.
이진 분류처럼 모델을 만들 수 있지만, 그렇게 한다면 True/False 값을 1/0으로 반환할 것이다. 다중 분류에서도 숫자로 바꿔 입력할 수 있지만 사이킷런에서는 문자열로 된 타깃값을 그대로 사용할 수 있다. 하지만, 그대로 사이킷런 모델에 전달하면 자동으로 '알파벳' 순으로 매겨지기 때문에 처음 입력했던 순서와 다를 수 있다.
이 샘플의 이웃은 'Roach'가 한 개로 1/3 , 즉 0.3333이고 'Perch'는 2개 이므로 0.6667이 된다. 앞서 출력한 네 번째 샘플의 클래스 확률과 같은 것으로 확인할 수 있다. 하지만 생각해보니, 어차피 확률은 네 개 중에 한 개이다. 0/3, 1/3, 2/3, 3/3 이 중에 있지 않을까? 만약 이렇게만 표기를 한다면 확률이라고 말하기 조금 애매한 부분이 있다.
<로지스틱 회귀>
# 기본미션 로지스틱 회귀는 이름은 회귀지만 '분류' 모델이다. 이 알고리즘은 선형 회귀와 동일하게 선형 방정식을 학습한다.
여기서 각 특성의 앞에 붙는 숫자(스칼라)는 가중치(weight) 혹은 계수라고도 말한다. z는 어떤 값도 가능하지만 확률이 되려면 결과값은 0~1 또는 0~100% 사이의 값이 되어야 한다. 그러기 위해서 z가 아주 큰 음수이거나 아주 큰 양수일 때, 0 혹은 1로 바꿔주는 함수가 있는데 이를 활성화 함수(activation function)라고 한다. 주로 시그모이드 함수(sigmoid)를 사용해서 이를 가능케 한다.
선형 방정식의 출력의 음수를 사용하여 자연 상수 e를 거듭제곱 하고 1을 더한 값의 역수를 취한다. 이런 복잡한 식을 거쳐 우측의 그림과 같은 그래프를 만들 수 있다. z가 무한하게 큰 음수일 경우 0에, 무한하게 큰 양수일 경우 1에 가까워 진다. z가 0일 때는 0.5가 된다. z가 어떤 값을 가지더라도 결과값은 0~1 사이에 있기 때문에 확률적으로 0~100% 의 확률을 보이는 것을 알 수 있다.
도미와 빙어를 타겟값으로 두고 비교 연산자를 사용하여 도미와 빙어에 대한 행만 골라낼 수 있다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
## 예측값 출력
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5]))
print(lr.classes_)
print(lr.coef_, lr.intercept_)
훈련한 모델을 사용해 처음 5개 샘플을 예측하면 첫번째 출력값이 나온다. 이후 처음 5개 샘플의 예측값을 출력하면 샘플마다 2개의 확률이 출력한다. 첫번째 열이 음성(0)에 대한 확률이고 두번째 열이 양성(1)에 대한 확률이다. 그럼 두 개의 항목('bream', 'smelt' 중 어떤 것이 양성 클래스인지 확인해보면 알파벳 순이기 때문에 'smelt'가 양성임을 확인할 수 있다.
선형회귀와 마찬가지로 위의 계수들을 통해 특성에 대한 가중치(계수)가 위와 같이 설정되는 것을 확인할 수 있다. 로지스틱 회귀 모델로 z값을 계산해 볼수도 있다.
decision_funtion() 메서드를 사용하여 z값을 출력할 수 있다. 이 값을 시그모이드 함수에 통과시키면 확률을 얻을 수 있는데 사이파이(scipy) 라이브러리의 expit() 메서드를 사용하여 얻을 수 있다.
from scipy.special import expit
print(expit(decisions))
출력된 값을 통해 decision_function() 메서드는 양성 클래스에 대한 z값을 반환하는 것을 알 수 있다. decision_funciont()의 출력이 0보다 크면 시그모이드 함수의 값이 0.5보다 크므로 양성 클래스로 예측한다.
<로지스틱 회귀로 다중 분류 수행하기>
로지스틱 회귀를 활용한 다중 분류도 이진 분류와 크게 다르지 않다. LogisticRegression 클래스는 max_iter 매개변수를 사용하여 반복 횟수를 지정하며 기본값은 100이다. 만약 반복 횟수가 부족하면 경고가 뜬다. 또한 릿지 회귀와 같이 계수의 제곱을 규제하는데, 이를 L2라고 부른다. L2 규제에서는 alpha를 사용한 규제를 했는데, LogisticRegression에서 규제를 제어하는 매개변수는 C이다. C는 alpha와 반대로 작을수록 규제가 커지고 기본값은 1이다.
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
훈련 세트와 테스트 세트에 대한 점수가 높으면서도 과대적합이나 과소적합으로 치우친 것 같지 않다.
이를 확인해보면, 첫번째 샘플은 세번째 열의 확률이 가장 높기 때문에 'perch'를 가장 높은 확률로 예측했고 두번째 샘플은 여섯번째 열의 확률이 높기 때문에 'smelt'를 높게 예측한 것을 알 수 있다. 또한 선형 방정식을 확인하여 계수를 출력해보면 5개의 특성을 사용하기 때문에 coef는 5개의 열이 있지만 행이 7개인 것으로 보인다. 즉, z를 7개를 계산한다는 것이다. 다중 분류는 클래스마다 z값을 하나씩 계산하고, 가장 높은 z값을 출력하는 클래스가 예측 클래스가 된다.
확률을 계산할 때는 이진 분류에서는 시그모이드 함수(sigmoid)를 사용했지만, 다중 분류에서는 소프트맥스(softmax) 함수를 사용한다. 소프트맥스(softmax) 함수란 여러 선형 방정식의 출력값을 0~1 사이로 압축하는 역할을 하는 함수이다. 또한 전체 합이 1이 되도록 만들기 위해 지수 함수를 사용하기 때문에 '정규화된 지수 함수'라고 부르기도 한다.
소프트맥스 함수는 각각의 지수함수를 전체 지수함수의 합으로 나눈 다음 그 s1~sn까지의 값을 더한 것이다. 모두 더하게 되면 분자와 분모가 같아지므로 결과값이 1이 되기 때문에 정상적으로 계산된 것을 알 수 있다. 시그모이드 함수(sigmoid)와 소프트맥스(softmax) 함수는 신경망에서도 나오는 개념이기 때문에 확실히 짚어두고 개념을 아는 것이 중요하다.
이진 분류에서처럼 먼저 z값을 구한 후 softmax 함수로 계산할 수 있다. softmax() 메서드의 axis매개변수는 소프트맥스를 계산할 축을 지정하는 매개변수다. axis=1로 지정한다면 각 행(샘플)에 대한 소프트맥스를 계산한다. 만약 axis 매개변수를 따로 지정하지 않으면 배열 전체에 대한 소프트맥스 계산이 진행된다. 출력 결과를 앞서 구한 proba 배열과 비교하면 정확히 일치하는 것을 확인할 수 있다.
04-2 확률적 경사하강법
시작하기 전에공급이 갑자기 늘면서 항목들이 추가되고, 그에 대한 샘플이 없는 경우에 어떻게 모델을 바꿔야할까?
<점진적인 학습>
데이터가 추가될 때마다 일정 간격을 두고 샘플을 추려서 새로운 모델을 만들면 되는 걸까? 하지만 시간이 지날수록 데이터는 늘어나리 때문에 서버도 기하급수적으로 늘려야할 수도 있다.
또 다른 방법은 새로운 데이터를 추가할 때 이전 데이터를 버림으로써 훈련 데이터 크기를 일정하게 유지하는 것ㅇ이다. 하지만 데이터를 버릴 때 중요한 데이터가 포함되어있으면 안 된다.
이렇게 데이터를 버리지 않고 새로운 데이터에 대해서만 훈련할 방법은 없을까? 이러한 훈련 방법을 점진적 학습이라고 부른다. 대표적인 점진적 학습 알고리즘은 확률적 경사 하강법(Stochastic Gradient Descent)이 있다.
<확률적 경사 하강법>
확률적 경사 하강법(Stochastic Gradient Descent)은 최적화 방법 중 하나이다. '확률적' 이라는 말은 random하다는 것과 같다. '경사'는 말 그대로 경사, 기울기, 즉 가중치(weight)를 이야기한다. '하강법'은 '내려가는 방법'이기 때문에 합쳐서 경사를 따라 내려가는 방법을 의미한다.
만약 우리가 산 꼭대기에서 하산을 하려고 하는데, 지도를 분실하거나 휴대폰의 배터리가 다 했다고 가정한다면 우리는 가장 빠르게 하산하기 위해 어떤 방법을 사용할까? 바로 경사가 가장 가파른 길을 선택할 것이다. 경사 하강법의 목적은 가장 빠르게 원하는 최소 지점에 도달하는 것이다.
한 걸음씩 내려올 때, 보폭이 너무 크면 최소 지점을 찾지 못할 수 있다. 또, 보폭이 너무 작다면 시간이 오래 걸릴 수 있다. 그렇기 때문에 가파른 길로 내려오되 적당한 보폭으로 내려와야 한다. 가장 경사가 가파른 길을 찾을 때는 전체 샘플이 아닌 '랜덤한' 샘플을 골라 내려올 것이다. 이처럼 훈련 세트에서 랜덤하게 샘플을 고르는 것이 확률적 경사 하강법이다.
만약 랜덤하게 샘플을 골라서 쓰다가 모든 샘플을 다 사용했는데, 내려오지 못했다면 다시 샘플을 채워넣고 랜덤하게 골라 내려오는 것이다. 이렇게 훈련 세트를 한 번씩 모두 사용하는 과정을 에포크(epoch)라고 부른다. 일반적으로 수십~수백번 이상의 에포크를 수행하는 편이다.
무작위로 내려오다가 실족하는 것이 걱정된다면 어떻게 해야할까? 그렇다면 랜덤 선택 시 1개가 아닌 여러 개의 샘플을 선택해서 내려갈 수 있다. 이렇게 여러 개의 샘플을 사용하는 것을 미니배치 경사 하강법(minibatch gradient descent)이라 한다.
한 번의 이동을 위해 전체 샘플을 사용할 수도 있는데 이를 배치 경사 하강법(batch gradient descent)라고 한다. 이는 가장 안정적이고 리스크가 적으르 수 있지만 그만큼 계산이 오래걸리고 컴퓨터 메모리를 많이 사용할 수 있다. 또, 데이터가 너무 많은 경우에는 모두 읽을 수 없을 수도 있다.
즉, 데이터의 성질이나 샘플의 갯수에 따라 경사 하강법의 종류가 나눠지며, 그 특성에 맞는 경사 하강법을 사용하면 된다.
<손실 함수>
손실 함수(loss function)는 어떤 문제에서 알고리즘이 얼마나 별로인지, 즉 '나쁜 정도'를 측정하는 함수다. 그래서 값이 작을수록 좋은 것이고, 손실 값이 낮은 쪽으로 경사하강법을 진행하는 것이 좋다. 확률적 경사하강법이 최적화할 대상이라고 이해를 해도 좋다.
분류모델에서는 정확도(accuracy)를 많이 봤었는데, 이진 분류에서는 예측과 정답이 맞는지 여부에 따라 양성과 음성으로 나뉜다. 위의 경우는 정확도가 0.5, 50%임을 알 수 있다. 이를 손실함수로 표현할 수는 없을까?
만약 위의 경우라면 정확도가 0, 0.25, 0.5, 0.75, 1의 다섯가지만 가능하다. 정확도가 이렇게 듬성듬성하다면 경사하강법을 이용해 조금씩 움직일 수 없다. 경사는 연속적이어야하기 때문이다. 조금 더 기술적으로 이야기한다면, 선은 점의 연속으로 되어있고, 점이 조금 더 촘촘해서 선을 이루고 즉 미분이 가능해야 한다. 결론적으로, 손실함수는 미분이 가능해야 한다.
그렇다면 연속적인 손실 함수를 만드는 법은 무엇일까?
<로지스틱 손실 함수>
로지스틱 손실 함수의 경우 예측값과 타깃값을 곱해서 사용할 수 있는데, 타깃이 0(false)인 경우는 곱하면 무조건 0이 되기 때문에 양성 클래스로 바꾸어 계산할 수 있다. 예측값과 타깃값 모두 1에서 빼서 변경이 가능하다.
예측 확률의 범위는 0~1 사이인데 로그 함수는 이 사이에서 음수가 되므로 최종 손실값은 양수가 된다. 로그함수는 0에 가까울수록 아주 큰 음수가 되기 때문에 손실을 아주 크게 만들어 모델에 큰 영향을 끼칠 수 있다.
즉, 타깃값이 1(true)일때는 음수로 바꾼다음 로그함수 적용을 하고, 타깃값이 0(false)일때는 1에서 뺀 다음 음수로 바꾸고 로그함수를 적용한다.
양성 클래스일때 확률이 1에서 멀어질수록 손실은 큰 양수가 된다. 음성 클래스일 때 확률이 0에서 멀어질수록 손실은 큰 양수가 된다. 이 손실 함수를 로지스틱 손실 함수(logistic loss function) 혹은 이진 크로스엔트로피 손실 함수(binary cross-entropy loss function)이라고 한다. 다중 분류에서 사용하는 손실함수는 크로스엔트로피 손실 함수(cross-entropy loss function)라고 한다.
* 회귀에서 사용하는 손실함수
회귀의 손실함수로는 평균 절댓값 오차를 사용할 수 있다. 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값이다. 혹은 평균 제곱 오차(mean squared error)를 많이 사용한다. 이는 타깃에서 예측을 뺀 값을 제곱한 다음 모든 샘플에 평균한 값이다. 이 값은 작을수록 좋은 모델이다.
<SGD Classifier>
확률적 경사하강법을 활용한 학습을 진행하기 전에, 데이터의 전처리를 진행해야 한다. 특성의 스케일값을 맞춘다.
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish_input = fish[['Weight', 'Length', 'Diagonal', 'Height', 'Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
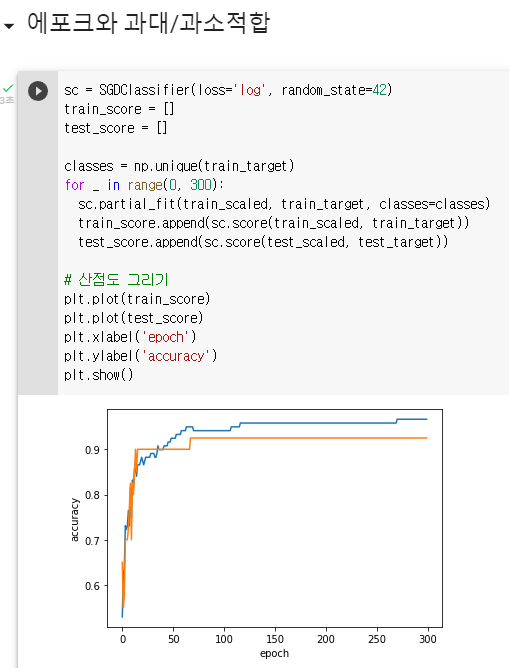
스케일값을 맞춘 다음 사이킷런에서 제공하는 확률적 경사 하강법 분류용 클래스를 사용한다. 객체를 만들 때 2개의 매개변수를 지정한다. loss는 손실함수의 종류를 지정하는 것이고, 여기서는 log로 지정하여 로지스틱 손실함수를 지정했다. max_iter는 에포크 횟수를 지정하는 것이다.
에포크마다 점수를 기록하기 위해 2개의 리스트를 준비한 후, 300번의 에포크를 반복한다. 그 다음 훈련에 대한 점수를 산점도로 나타내면 위와 같은 그래프로 나타난다. 위의 그래프를 통해, 100번째 epoch 이후로는 훈련 세트 점수와 테스트 세트 점수가 조금씩 벌어지는 것을 확인할 수 있다. 또한, 에포크 초기에는 과소적합으로 점수가 낮은 것을 알 수 있다. 결론적으로 100회가 적절한 epoch로 보인다.
SGDClassifier에서 반복횟수를 100회로 지정한 후 훈련을 진행해보았다. SGDClassifier는 일정 에포크동안 성능이 향상되지 않으면 자동으로 멈춘다. tol 매개변수에서 향상될 최솟값을 지정할 수 있다. None으로 지정한다면 자동으로 멈추지 않고 max_iter만큼 무조건 반복된다.
* 확률적 경사하강법을 사용한 회귀모델은 SGDRegressor이다.
SGDClassifier의 loss 매개변수의 기본값은 'hinge'이다. 힌지 손실(hinge loss)은 서포트 벡터 머신(support vector machine)이라 불리는 알고리즘을 위한 손실 함수이다. 이는 또 다른 머신러닝 알고리즘이다. 서포트 벡터 머신에서는 다른 포스팅에서 딥하게 설명하도록 하겠다. SGDClassifier는 여러 종류의 손실함수를 loss 매개변수에 지정하여 알고리즘에 사용할 수 있다.
# 힌지 손실을 사용한 훈련
sc = SGDClassifier(loss='hinge', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
log함수가 아닌 힌지함수를 사용하여 loss값을 지정해주었더니 점수가 달라졌다.
● 마무리
다양한 회귀, 분류 모델에 사용되는 알고리즘을 통해 배웠다. 점진적 학습을 할 수 있는 확률적 경사 하강법, 로지스틱 회귀 모델 등으로 요즘처럼 데이터가 큰 빅데이터를 다룬다면 아주 유용할 것이다. 손실함수가 어떤 것인지와 적당한 에포크 횟수를 캐치하는 방법도 학습했다.
우리는 많은 경우에 예측을 한다. 비단 현대사회뿐만 아니라 수천년전부터 사람들은 예측을 하는 것에 관심이 많았다. 고대 바빌로니아의 예측가는 썩은 양의 간에서 구더기의 분포를 미래를 예언하기도 했다. 이처럼, 계획을 세우는 데 있어 예측은 큰 도움이 된다. 예측가능성은 다음과 같은 요인에 의존하게 된다.
영향을 주는 요인을 얼마나 잘 이해할 수 있는지
사용할 수 있는 데이터가 얼마나 많은지
예측이 우리가 예측하려는 것에 영향을 줄 수 있는지 여부
전기 수요 예측의 경우는 위의 조건이 모두 맞기 때문에 상당히 정확한 편이다. 하지만, 환율 예측의 경우에는 2번의 조건만 만족하기 때문에 예측이 정확하지 않은 경우도 있다. 예를 들어 환율 예측은 환율 자체에 직접적으로 영향을 주기도 한다. 즉, 예측 자체 때문에 예측이 맞는 상황이 되기도 하는 것이다. 이러한 상황을 '효율적인 시장 가설(efficient market hypothesis)' 라고 볼 수 있다.
좋은 예측이란 과거 데이터에서 존재하는 진짜 패턴과 관계를 잡아낸다. 환경이 변하는 경우에 예측이 불가능할 것이라고 대부분 생각한다. 하지만 모든 환경은 변화고, 좋은 예측 모델이랑 변하는 '방식'을 잡아내는 것이다. 즉, 환경이 변하는 방식이 미래에도 계속될 것이라는 가정 하에 예측을 하는 것이다.
1.2 예측, 계획 그리고 목표
예측은 경영을 함에 있어 큰 도움을 줄 수 있는 업무이다. 상세하게 보면 크게 세 분류로 나눠 정의해 볼 수 있다.
예측(Forecasting) : 주어진 이용가능한 모든 정보를 바탕으로 가능한 한 정확하게 미래를 예측하는 것
목표(Goals) : 발생하길 기대하는 희망사항. 목표가 실현 가능한지에 대한 예측 없이 목표를 세우는 경우도 있다.
계획(Planning) : 예측과 목표에 대한 대응. 예측과 목표를 일치시키는 데 필요한 행동을 결정하는 일을 포함한다.
예측은 용도 및 기간에 따라 세 분류로 나눠볼 수 있다.
단기 예측 : 인사, 생산, 수송 계획, 수요 예측
중기 예측 : 원자재 구입, 신규 채용, 장비나 기계 구입
장기 예측 : 보통 전략적으로 계획을 세우는 데 사용한다. 시장 기회, 환경 요인, 내부 자원을 반드시 고려해야 한다.
1.3 어떤 것을 예측할 지 결정하기
예측 프로젝트의 초기 단계에서는 어떤 것을 예측할지 결정해야 한다. 예를 들어 생산 환경에서 물품에 대한 예측이 필요하다면,
모든 생산 라인에 대한 것인가? 혹은 생산 그룹에 대한 것인가?
모든 판매점에 대한 것인가? 지역별 판매점 그룹에 대한 것인가? 전체 판매량에 대한 것인가?
주별 데이터인가? 월별 데이터인가? 연간 데이터인가?
등을 고려해야 할 것이다. 예측 범위, 예측 빈도도 고려해야 한다. 또한 예측값을 만들기 전, 예측값을 사용할 사람과 대화하며 사용자의 필요에 대한 이해도 필요할 것이다. 앞의 과정이 이뤄지고 나서야 예측에 필요한 데이터를 찾아야 한다. 예측을 하는 사람이 가장 시간을 많이 쏟는 부분은 데이터를 찾고 모아서 분석하는 부분이다.
1.4 예측 데이터와 기법
어떤 데이터를 사용할 수 있는지에 따라 예측 기법이 달라진다. 만약 이용할 수 있는 데이터가 없거나, 이용할 수는 있지만 예측에 상관 없는 데이터라면, 정량적인 예측 기법(Quantitive Forecasting)을 사용해야 한다.
과거 수치 정보를 사용할 수 있을 때
과거 패턴의 몇 가지 양상이 미래에도 계속될 것이라고 가정하는 것이 합리적일 때
위의 두 가지 조건을 만족할 때 정량적인 예측을 사용할 수 있으며 여러 정량적 예측 기법이 있다. 대부분 정량적 예측 문제는 일정한 간격으로 모은 시계열 (LSTM) 데이터나 특정 시점에서 모은 횡단면(cross-sectional) 데이터를 사용한다.
시계열 예측
IBM 일별 주가
월별 강우량
Amazon의 분기별 판매 결과
Google의 연간 수익
위와 같이 시간에 따라 순차적으로 관측된 데이터를 시계열로 다룰 수 있다. 시계열을 예측할 때, 목표는 관측값이 미래에 계속될 것인지 예측하는 것이다.
호주 맥주의 분기별 생산량이며, 파란색 부분은 다음 2년에 대한 예측값이다. 예측값들이 과거 데이터에서의 패턴을 얼마나 잘 캐치하고 다음 2년에 대해 잘 모사하는지 주목해서 봐야 한다.
어둡게 그늘로 표시한 영역은 80% 예측 구간(prediction interval)을 의미한다. 즉, 미래값이 80%의 확률로 어두운 그늘로 표기한 영역에 들어갈 것으로 예측하는 것이다. 밝은 그늘로 표시한 영역은 95% 예측 구간을 의미한다. 이러한 예측 구간은 예측의 불확실성을 나타낼 때 유용하다.
가장 단순한 시계열 예측 기법은 예측할 변수 정보만 이용하고, 변수의 행동에 영향을 미치는 다른 요인들은 고려하지 않는다. 시계열 예측용 모델에는 분해모델 (decomposition models), 지수평활 (exponential smoothing models) ,ARIMA 모델 등이 있다.
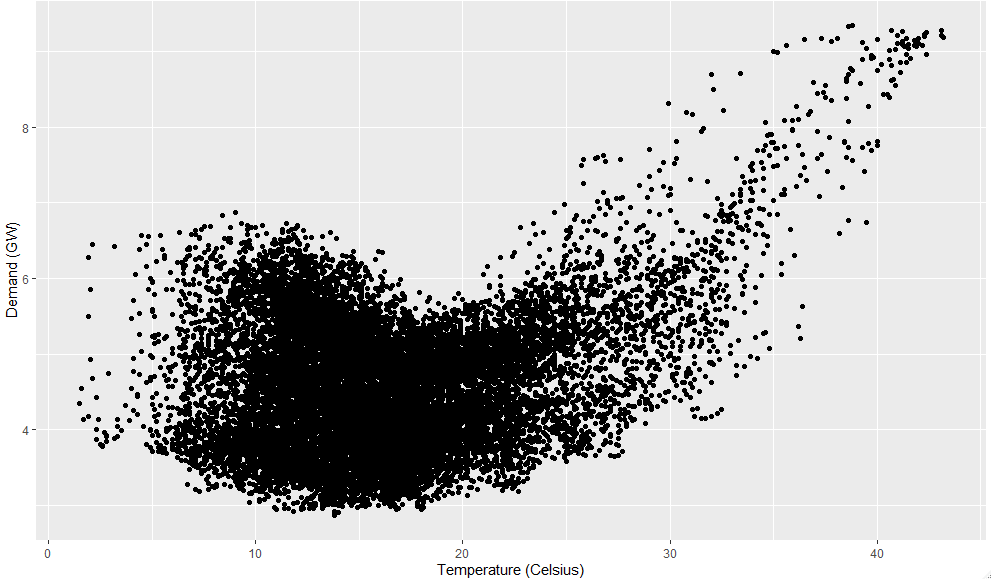
예측 변수와 시계열 예측
예측 변수는 시계열을 예측할 때 유용하다. 예를 들어 여름 동안 더운 지역의 시간당 전기 수요(ED, electricity demand)를 예측한다면 예측 변수를 고려해야할 것이다.
현재 기온, 경제 상황, 인구, 시간, 요일, 오차 중 어떤 것이 전기 수요의 변동을 일으키는지 설명할 때 도움이 되기 때문에 이 모델을 설명 모델(explanatory model)이라고 부른다.
여기에서 설계한 모델의 t는 현재시간, t-1은 한 시간 전, t+1은 한 시간 후로 변수의 과거 값으로 미래 예측을 한다.
위의 두 모델의 특징을 결합한다면 위와 같이 혼합된 모델링을 할 수 있다. 이러한 모델은 동적 회귀 (dynamic regression) 모델, 패널 데이터(panel data) 모델, 종단(longtudinanl) 모델, 수송 함수(transfer function) 모델, 선형 시스템(linear system) 모델 등 다양한 종류의 모델이 있다.
이러한 모델들은 변수의 과거 값만 다루지 않고 다른 변수에 대한 정보도 포함하기 때문에 유용하게 사용할 수 있다. 하지만 설명 모델이나 혼합된 모델 대신에 시계열 모델을 선택할 수도 있는 다양한 경우가 있다.
변수의 행동에 영향을 주는 관계를 측정하기가 어려운 경우
관심 있는 변수를 예측하려면 다양한 예측 변수의 미래값을 알 필요가 있거나 예측할 필요가 있는 경우
주된 관심이 '왜' 일어나는지가 아니라 '무엇'이 일어나는지에 있는 경우
이처럼 데이터나 모델의 정확도, 사용될 방식에 따라 예측에 사용할 모델이 달라진다.
1.6 예측 작업의 기본 단계
문제 정의
정보 수집
예비 분석
모델 선택 및
예측 모델 사용 및 평가
1.7 통계적 예측 관점
예측값은 확률 변수(random variable)가 비교적 높은 확률로 취할 수 있는 값들의 범위를 제시하는 예측 구간(prediction interval)을 수반한다.
우리가 아는 A 라는 값이 주어진 상황에서의 무작위 변수가 가질 수 있는 값은 확률 분포(probability distribution) 라고 하며, 예측을 함께 제시했을 때 예측분포(forecast distribution)라 한다.